
背景
音声チャットアプリケーションは「長寿命接続ライフサイクル」(long connection lifecycle)を必要であり、このようなサービスを Amazon EKS に移行するのは非常に困難です。
ソニー・インタラクティブエンタテインメント(SIE)による PSN 音声チャットサーバーの移行に関するセッションは、内容の薄い多くの講演の中で、その技術的な深さで私に強い印象を残しました。Kubernetes と格闘した日々を思い出しながら、早速本題に入りましょう。
アジェンダ
- 長時間接続アプリケーションがコンテナ化およびクラウドネイティブ化の過程で直面する普遍的な課題、特に「セッションの継続性」と「弾力的なスケーリング」について説明します。
- Agones を利用してこれらの課題を解決し、音声チャットサーバーを Amazon EKS に成功裏に移行した方法。
- ユーザーへの影響を最小限に抑えつつ、スムーズかつ柔軟にトラフィックを移行する方法。
長時間接続アプリケーションの課題
長時間接続アプリケーションの特性
- クライアントは同一のサーバーと長期間のセッションを確立・維持し、セッション中に状態を保持します。
- サーバーは各セッションの実行状態を維持する必要があるため、セッション中のサーバー中断はユーザーエクスペリエンス(UX)を著しく損ないます。
- スケールアウトでもスケールインでも、セッションの継続性を最優先する必要があります。
長寿命接続アプリケーションのシナリオ例
- WebSocket を使用する常時接続アプリケーション(オンラインコラボレーションツール、メッセージプッシュなど)。
- ゲームサーバーやビデオチャットなどの他のリアルタイム通信システム。
- gRPC ストリーミングを使用して双方向通信を行うマイクロサービス。
- 多数の IoT センサーやデバイスとの接続を維持する必要があるサーバー。
PSN 音声チャットサーバーの特性
- 前述のセッション継続性に加え、トラフィックの「スパイク」特性が強調されています。グラフの曲線は、トラフィックがピークとオフピークの間で激しく変動することを示しています。
- リアルタイム性を実現するため、通信プロトコルには UDP を採用しています。これにより、2つの重要なポイントが生まれます:
- クライアントはロードバランサーを介さず、サーバーと直接通信します。
- そのため、サーバーのパブリック IP アドレスとポート番号をクライアントに通知する仕組みが必要です。
アーキテクチャの課題
Amazon EC2 での運用における課題
- コスト最適化の困難さ:セッションを維持しながらのスケールインは非常に難しく、AWS の自動スケールイン機能を効果的に活用してコストを削減することができません。さらに、EC2 インスタンス(仮想マシン)の起動速度はコンテナよりも遅いため、突発的なトラフィック(スケールアウト)に対応するために、より多くの冗長サーバーを確保する必要があり、コストがさらに増加します。
- 認知的負荷:PSN チームの他のサービスは既に EKS に移行しており、クラウドネイティブな CI/CD プロセスを持っています。しかし、音声チャットという「技術的サイロ」は EC2 に留まっており、チームは2つの全く異なる技術スタックと運用体系を維持する必要があり、これが大きな「認知的負荷」(Cognitive Load)とメンテナンスコストをもたらしていました。
ネイティブ Kubernetes の3つの核心的な障害
- セッション継続性の保証:Pod の再スケジューリングや障害による再起動は、進行中のセッションを中断させ、ユーザーに影響を与えます。
- スケールイン/スケールアウトの制御:自動スケールインが、ユーザーにサービスを提供中の Pod を「誤って強制終了」させてしまう可能性があります。一方、スケールアウトが十分に速くないと、新規ユーザーが待たされたり、接続に失敗したりします。
- UDP 通信の処理:K8s では、Pod の UDP ポートをパブリックに公開すること自体が面倒です。さらに、Pod の IP とポートはスケーリングや再スケジューリングによって変化するため、この動的なアドレスをクライアントにどう通知するかが大きな課題となります。
解決策:Agones

- ゲームサーバー向けに設計された、オープンソースの Kubernetes 拡張機能です。
- 動作原理:カスタムリソース(CRD)とカスタムコントローラーを用いて K8s を拡張し、K8s が「セッションベースのリアルタイム通信」アプリケーション(すなわち GameServer Pod)のライフサイクルを理解し、管理できるようにします。
コア機能
- セッション中の Pod の保護:Agones は Pod にセッションステータスを付与し、ユーザーにサービスを提供中の Pod が意図せず終了されることを防ぎ、セッションの継続性を保証します。
- Pod リソースの事前確保:
FleetとFleetAutoscaler機能により、「ウォームアップ済み」の Pod のバッファプールを維持できます。トラフィックのピーク時には、即座に新しいサーバーを割り当てることができ、スケールアウトの遅延問題を解決します。 - Pod へのパブリック IP と UDP ポートの割り当て:Agones は各 Pod に直接、独立したパブリック IP と UDP ポートを割り当てることができ、クライアントが直接接続できるようになります。これにより、前述の UDP ダイレクト接続モデルが完璧に実現されます。
- K8s の「セッション保証」の難題 -> Agones がステータス保護で解決。
- K8s の「スケールアウト遅延」の難題 -> Agones がバッファプール(Fleet)で解決。
- K8s の「UDP ダイレクト接続」の難題 -> Agones が Pod への直接 IP・ポート割り当てで解決。
アーキテクチャ図
移行前の EC2 アーキテクチャ - “Before”
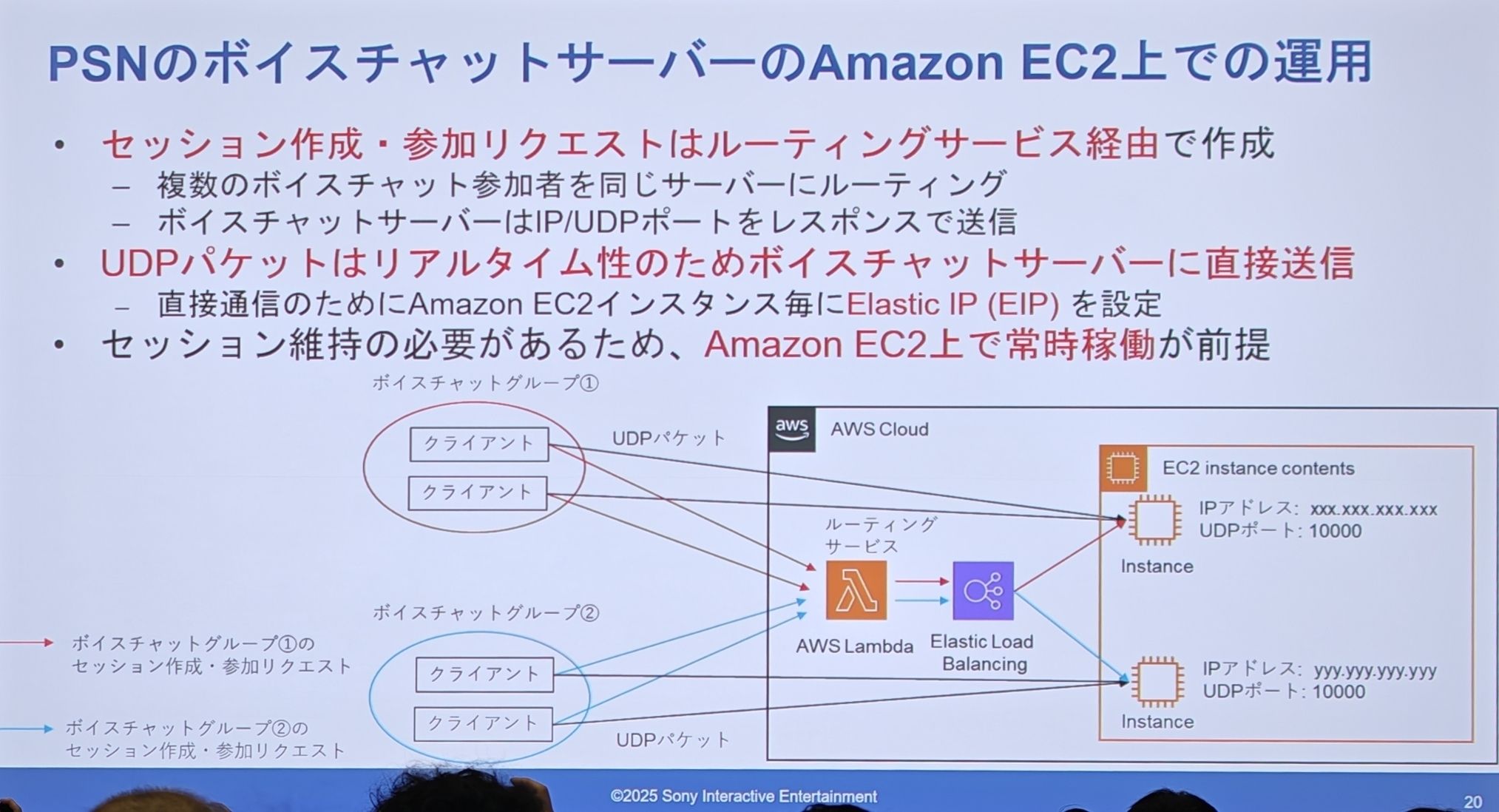
- クライアントの「セッション作成/参加」リクエストは、「ルーティングサービス」(図では AWS Lambda + ELB)によって処理されます。
- ルーティングサービスは、同じチャットグループの複数のユーザーを同じ EC2 サーバーに誘導する役割を担います。
- UDP ダイレクト接続を実現するため、各 EC2 インスタンスには**固定の Elastic IP(EIP)**が設定されています。
- クライアントは IP とポートを取得した後、ルーティングサービスをバイパスし、直接 EC2 サーバーに UDP パケットを送信します。
移行後の新アーキテクチャ図 - “Now”
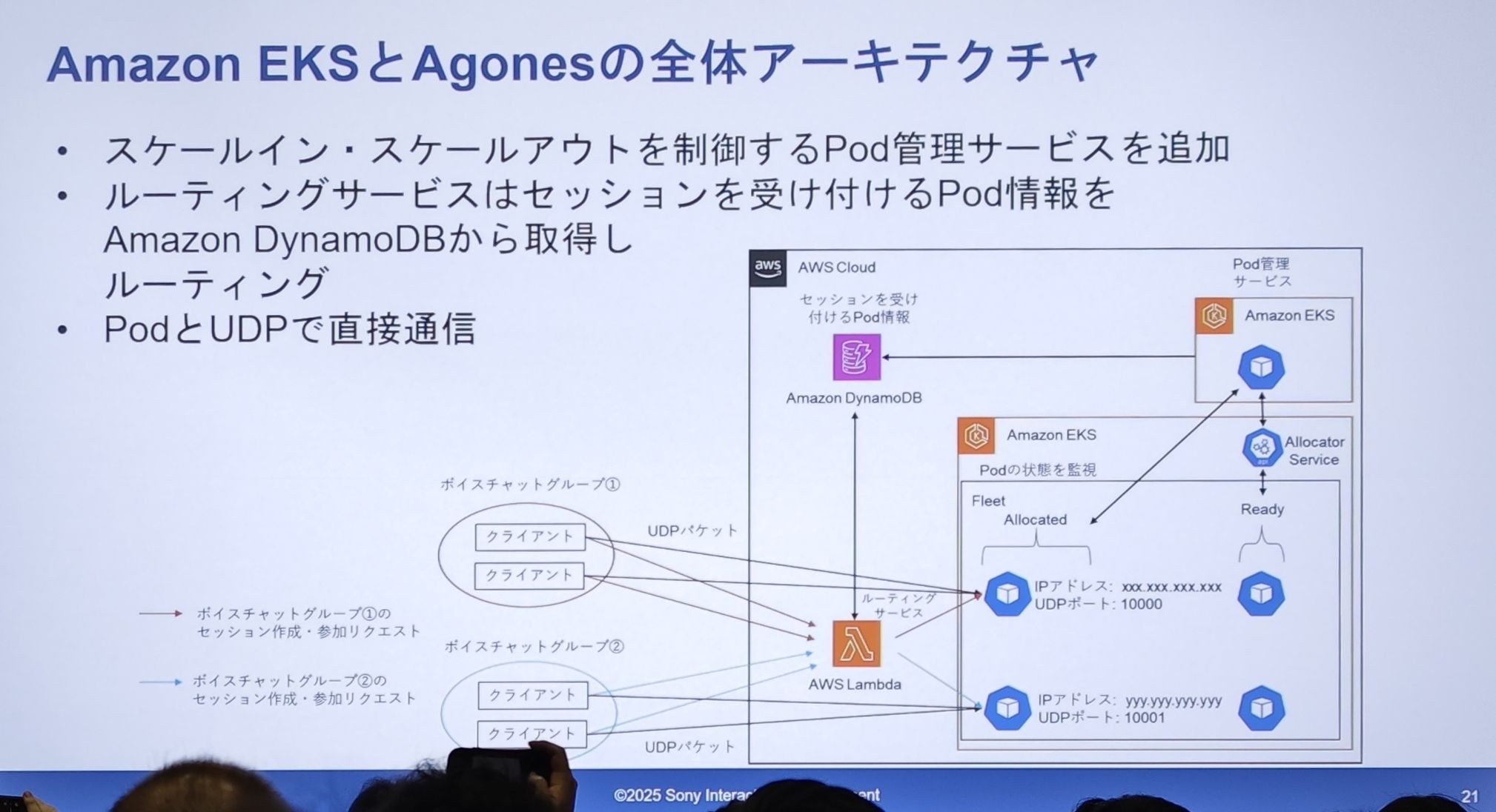
- Pod 管理:EKS 内で、Agones の
FleetがReady状態の Pod のバッファプールを維持します。 - セッション割り当て:ルーティングサービス(Lambda)がセッションリクエストを受け取ると、もはやサーバーに直接アクセスしません。Agones の
Allocator Serviceにリクエストを送り、アロケータがFleetからReadyの Pod を取り出し、その状態をAllocatedに変更します。 - 情報の中継:割り当てられた Pod の接続情報(パブリック IP、UDP ポート)は Amazon DynamoDB テーブルに保存されます。
- ルーティングロジック:ルーティングサービス(Lambda)が DynamoDB をクエリし、利用可能な Pod の情報を取得してクライアントに返します。
- 直接通信:クライアントは動的に割り当てられた IP とポートを取得した後、以前と同様に、この Pod と直接 UDP 通信を行います。
- 核心的な分離:DynamoDB を「サービスレジストリ」として導入することで、サービスリクエスト(コントロールプレーン)とサービスインスタンス(データプレーン)が完璧に分離されました。
- 動的な置き換え:EC2 インスタンスは EKS の Pod に、固定 EIP は動的に割り当てられる IP に置き換えられました。
- インテリジェントなスケジューリング:Agones が「インテリジェントなスケジューラー」の役割を果たし、Pod のライフサイクル管理とバッファリングを担当することで、高性能と高可用性を確保しています。
セッション割り当ての詳細
Agones の設計(専用 Pod)
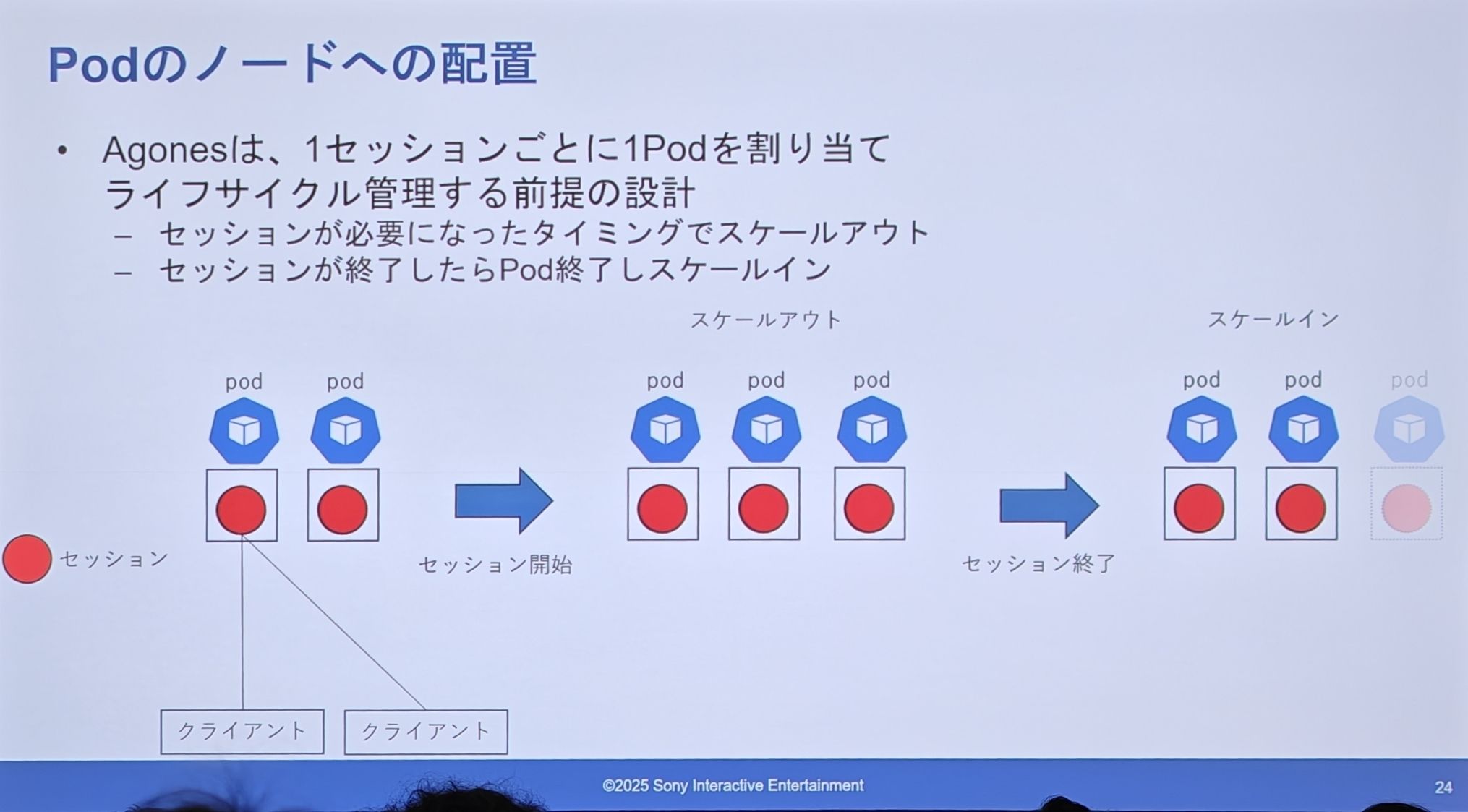
- 1セッション = 1 Pod:Agones の設計思想は、個別のセッションごとに専用の Pod を割り当てることです。
- オンデマンドスケーリング:新しいセッションが必要になると、バッファプールから Pod を取り出し(スケールアウト)、セッションが終了するとその Pod は破棄されます(スケールイン)。
専用 Pod の問題点:
- サーバーコストの増加:このモデルは非常に「贅沢」です。1つのセッションが Pod の最小リソース(特に CPU)を使い切らない場合、無駄が生じます。さらに、各 Pod(つまり各セッション)にサイドカーコンテナが必須であり、これ自体が大きなオーバーヘッドとなります。
- インフラへの影響:
- VPC 内の IP アドレス枯渇:数百万のオンラインセッションがあれば、数百万の Pod IP が必要になり、VPC の IP アドレスプールに大きな負荷がかかります。
- etcd とプラグインへの負荷:Kubernetes クラスタのメタデータはすべて etcd に保存されます。数百万の Pod の作成と破棄は、クラスタの頭脳である etcd や他のプラグインに深刻なパフォーマンス負荷をもたらします。
PSN の実際の設計(共有 Pod)
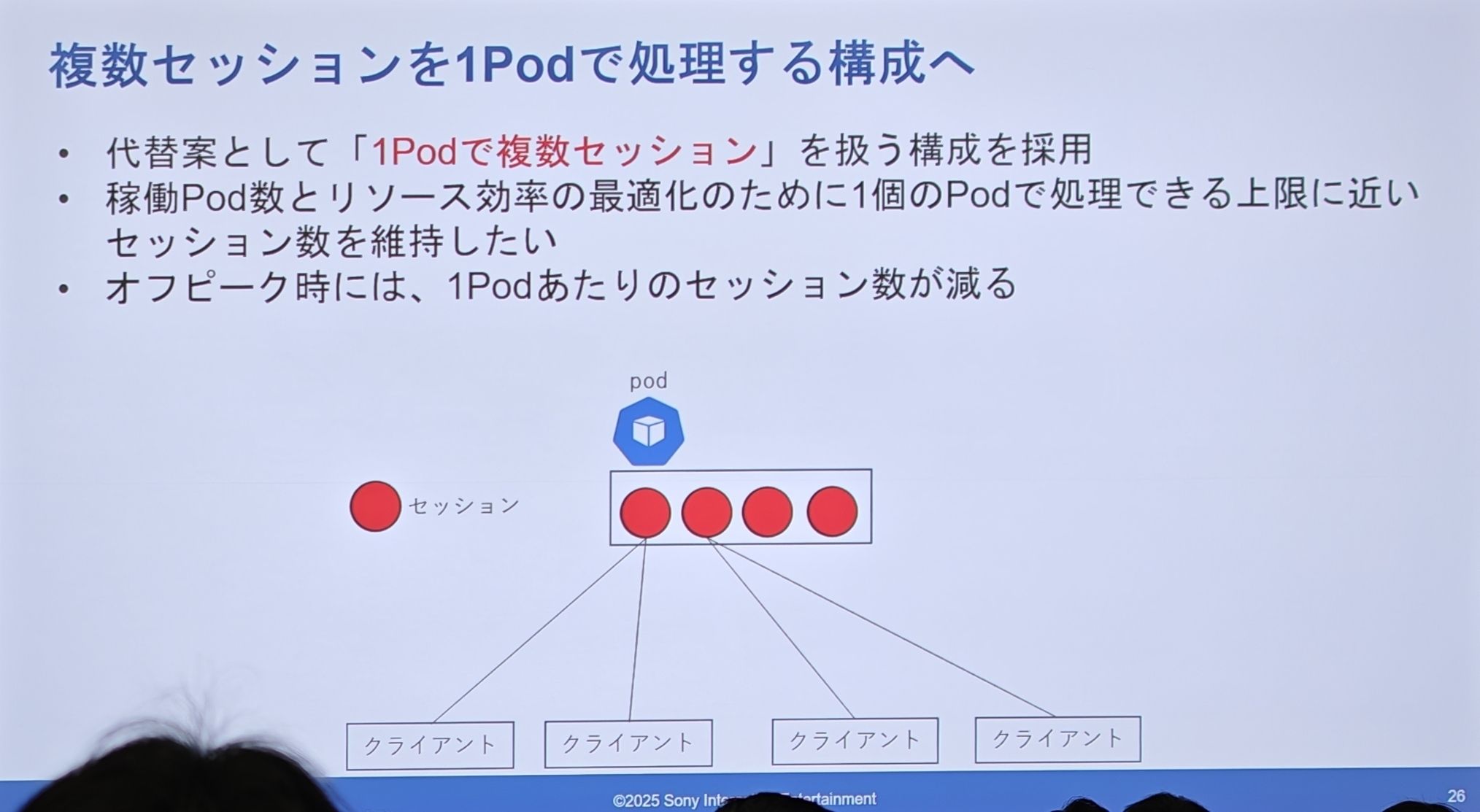
- 目標はリソース効率を最適化し、各 Pod を可能な限り最大負荷で稼働させることです。
- オフピーク時には、各 Pod がホストするセッション数は自然に減少します。
- 1つの Pod 内部で、複数の独立したセッションが実行されます。これは本質的に、Pod 内部で軽量なスケジューリング・管理レイヤーを実装していることになります。
しかし、共有 Pod でのスケーリングは非常に複雑になります:
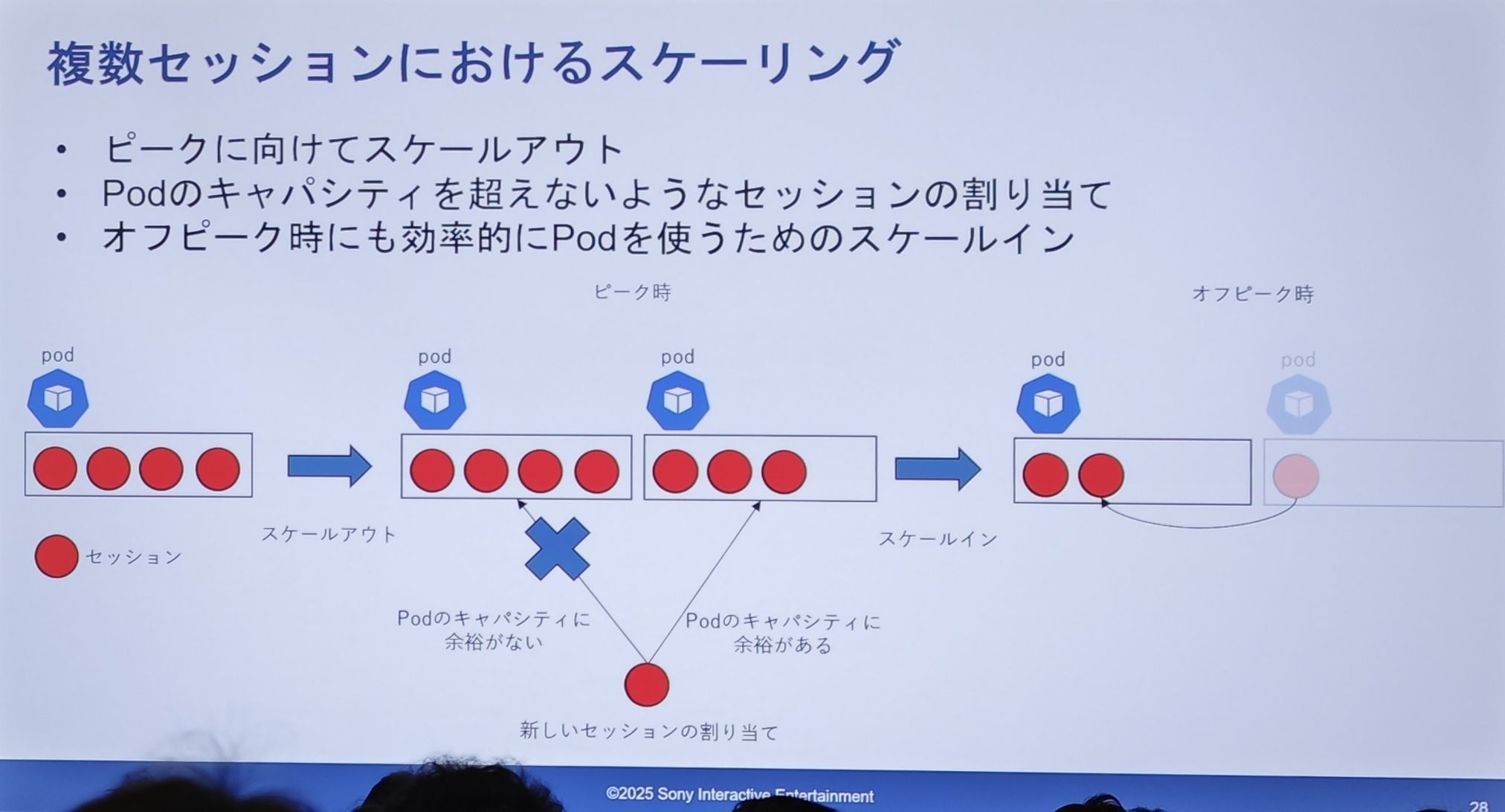
- スケールアウト:ピークに対応するために Pod 数を増やします。新しいセッションリクエストが来ると、「キャパシティ」のある Pod を探して割り当てます。図では、満杯の Pod は新しいリクエストを拒否し、空きのある Pod が受け入れています。
- スケールイン:オフピーク時に Pod を効率的に利用するため、スケールインが必要です。図では「セッションのマージ」プロセスが示されています。ある Pod 上のセッションを、空きのある別の Pod に移行させ、完全に空になった Pod を破棄します。
Agones の設計(Pod ステートマシン)
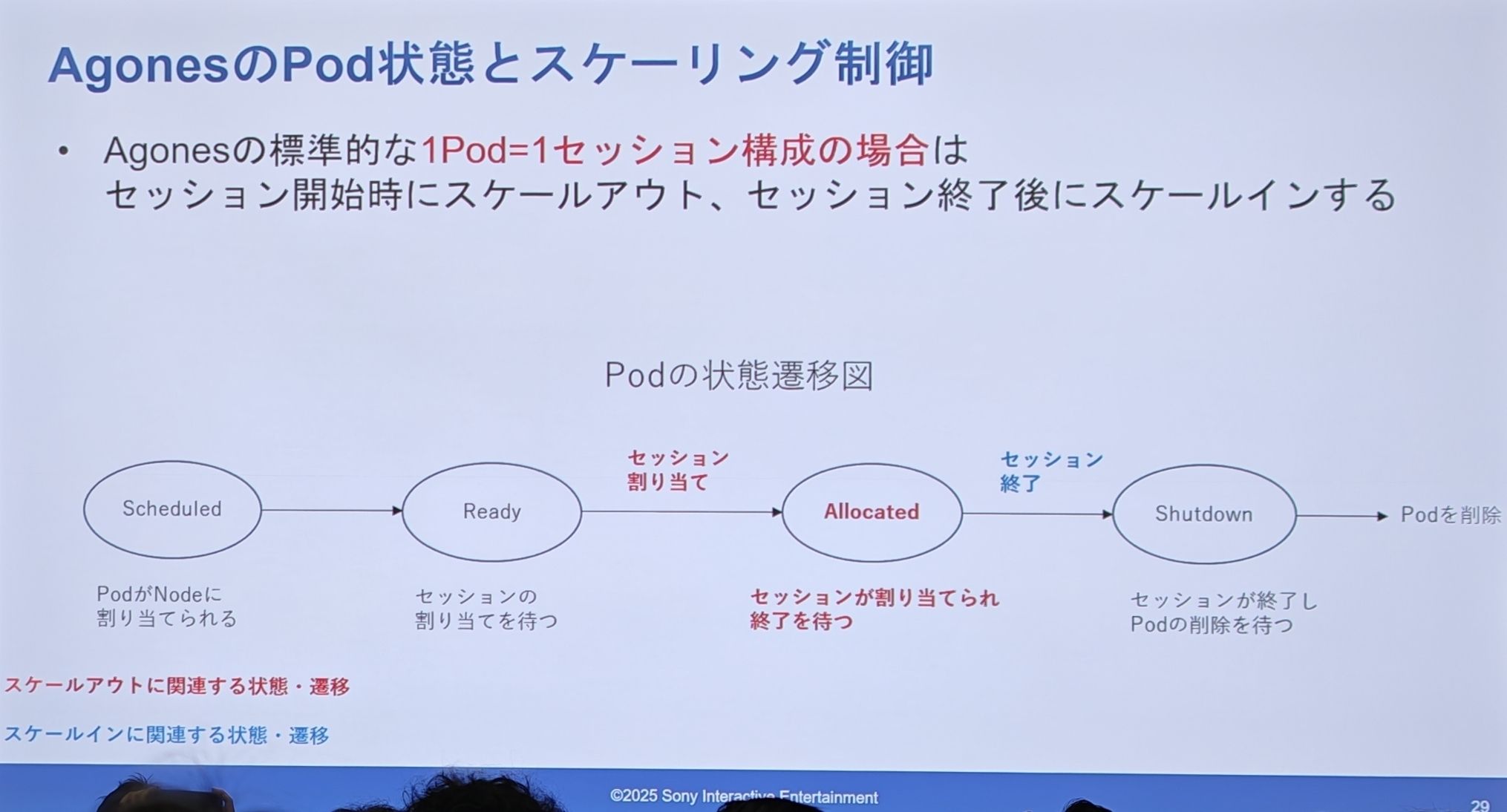
-
Scheduled -> Ready (割り当て待機中) -> Allocated (割り当て済み、セッション提供中) -> Shutdown (シャットダウン中) -> Pod 削除。
-
スケールアウトはセッション開始時(Ready -> Allocated)に発生し、スケールインはセッション終了後に発生します。
PSN の実際の設計(Pod ステートマシン)
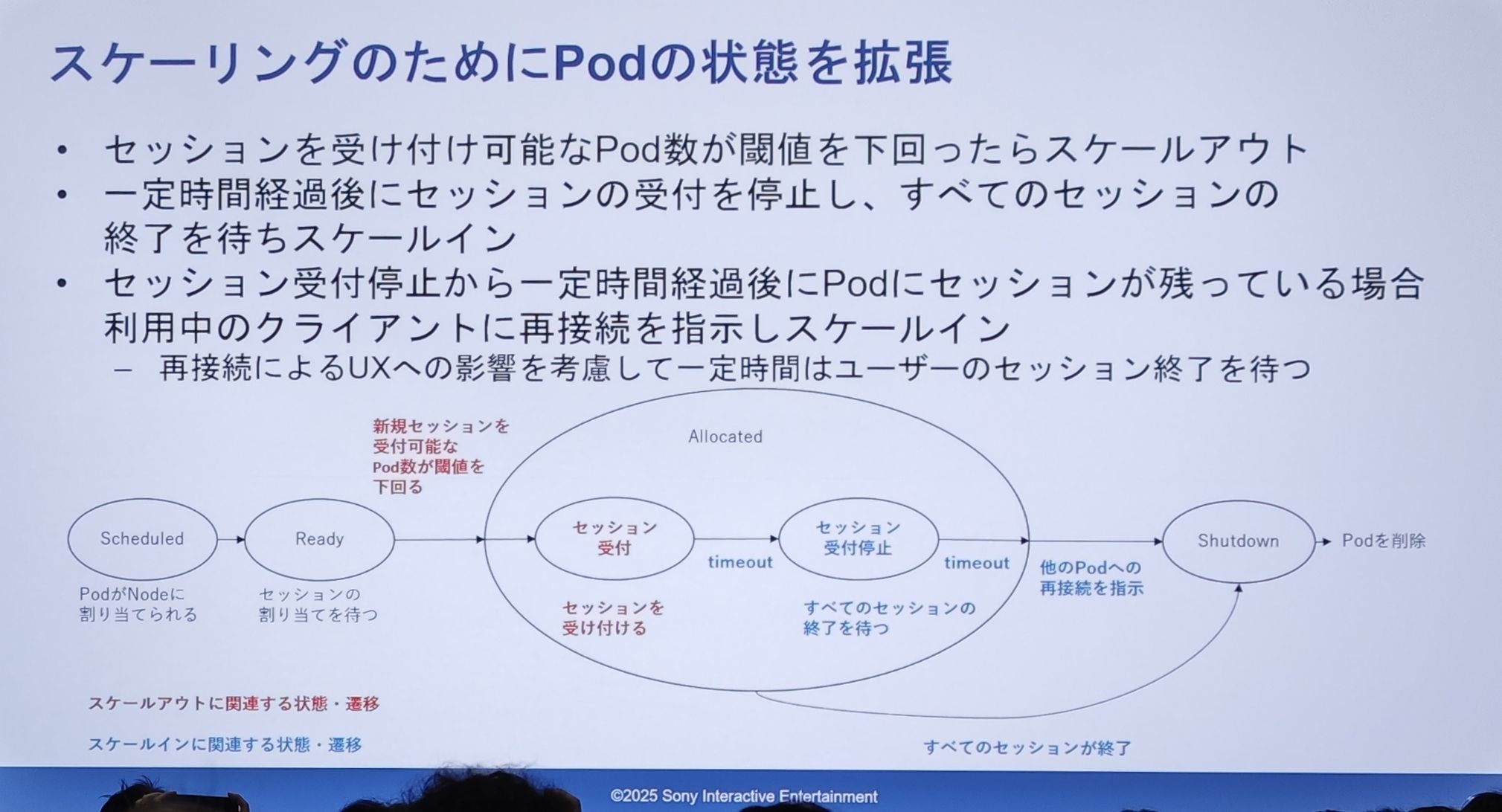
- スケールアウトロジック:新しいセッションを受け入れ可能な Pod の数が特定のしきい値を下回ったときに、スケールアウトがトリガーされます。
- スケールインロジック(核心部分):
- Pod はまず「新規セッション受付停止」状態になります。
- その後、一定時間待機し、Pod 内の既存セッションが自然に終了するのを待ちます。
- タイムアウト後も Pod 内にセッションが残っている場合、システムはこれらの「居座り」クライアントに「再接続してください」という指示を能動的に送信し、他の Pod への移行を促します。
- すべてのセッションが終了して初めて、Pod は
Shutdown状態に入り、最終的に削除されます。
スケールイン実装の詳細:Fleet Autoscaler
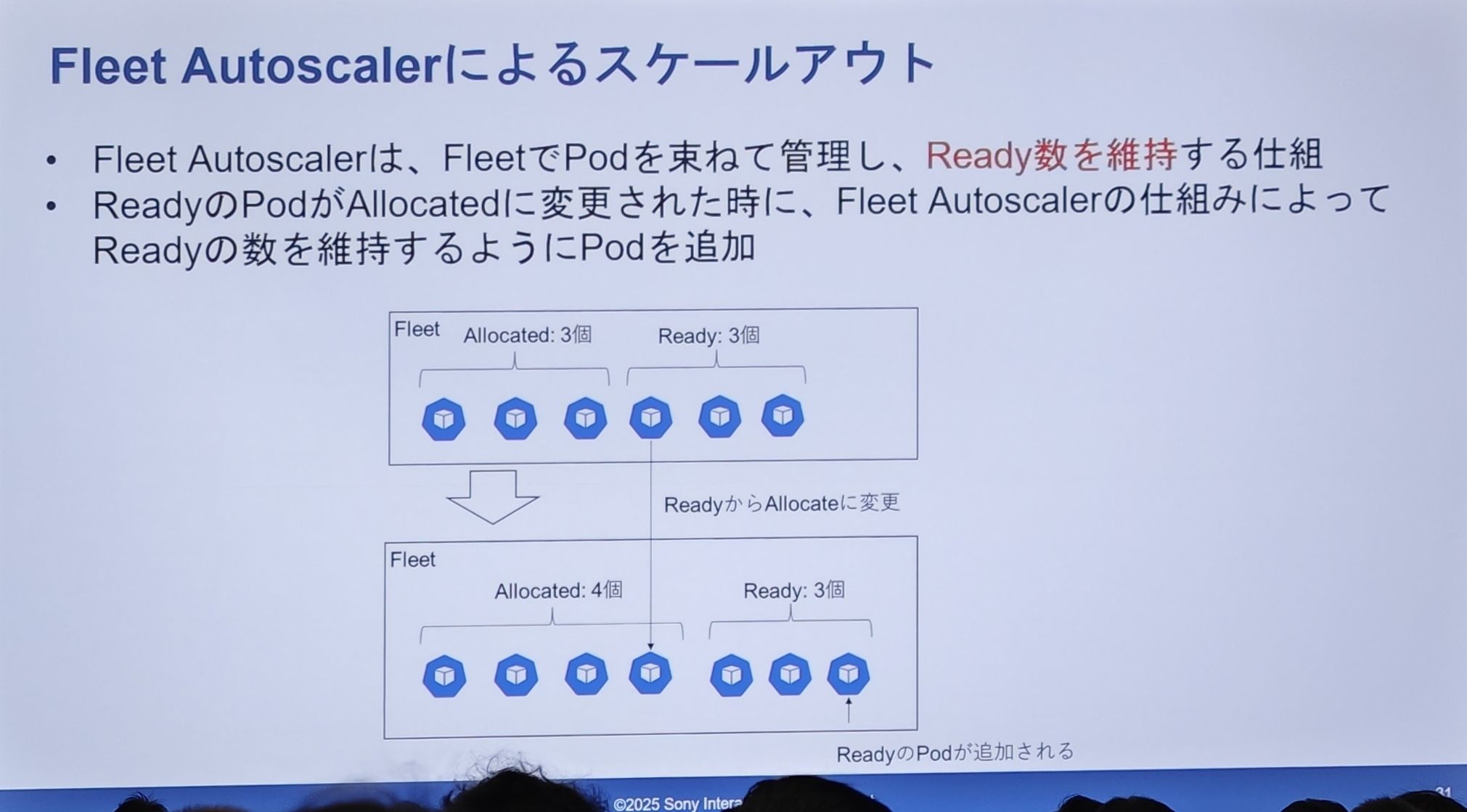
Fleet AutoscalerはFleet(Pod の集団)内のReady状態の Pod 数を監視します。Readyの Pod がセッションに割り当てられてAllocated状態に変わると、Readyの Pod 数が減少します。Fleet Autoscalerはこれを即座に検知し、自動的に新しい Pod を作成してReadyバッファプールを補充し、その数を事前設定されたレベルに維持します。
Ready プールが3から2に減ると、システムはすぐに1つ補充して3に戻します。これにより、いつでも「空席あり」のサーバーが確保され、ユーザーの待機時間が極めて短く保たれます。
Agones の設計(セッション割り当て)

- 標準的な Agones のフローは:セッションリクエスト受信 -> Allocator サービスを呼び出して
Readyの Pod をAllocatedに変更 -> 割り当てリクエスト。 - この Allocator サービスはリクエストをバッチ処理するため、最大 500ミリ秒の遅延が発生します。
- 音声チャットのようなリアルタイムアプリケーションにとって、起動時に半秒の遅延は許容できず、ユーザーエクスペリエンスに深刻な影響を与えます。
PSN の実際の設計(セッション割り当て)

核心的な解決策:分離! 「ユーザーがセッションをリクエストする」という超高速応答が必要な操作と、「システムが Pod を割り当てる」という比較的遅いバックグラウンド操作を分離します。
- ユーザーのセッションリクエスト(Lambda 経由)は、もはや直接 Pod の割り当てをトリガーしません。
- Lambda は DynamoDB をクエリし、事前に割り当て済みで、いつでもセッションを受け入れ可能な Pod のリストから、即座に利用可能な Pod 情報を取得します。
- そして、500ms かかる割り当て操作は、「Pod 管理サービス」がバックグラウンドで事前に、能動的に完了させ、割り当て済みの Pod 情報を DynamoDB のリストに登録しておきます。
Ready Pod バッファプールの上に、さらに第二のバッファプールを構築しました。これは Allocated 状態で、いつでもサービス提供可能な Pod で構成されるバッファプールです(つまり DynamoDB のリスト)。ユーザーのリクエストは常にこのホットスタンバイの「セカンダリバッファ」からデータを取得するため、バックグラウンドの500ms の遅延がユーザーから完全に隠蔽されます。
スケールアウト実装の詳細:いつ自動スケールアウトをトリガーするか

- いつセッション受付を停止するか:個々の Pod が CPU 使用率やホストするセッション数で満杯になった場合、新規セッションの受付を停止し、DynamoDB の利用可能リストから削除されます。
- いつバックグラウンドスケールアウトをトリガーするか:Pod 管理サービスは、DynamoDB の「新規セッション受付可能な Pod」の数を継続的に監視します。この数が設定されたしきい値を下回ると、即座に Agones の Allocator サービスにリクエストを送り、新しい Pod を申請し、500ms のプロセスを経て、新しく準備できた Pod を DynamoDB のリストに補充し、将来の使用に備えます。
これが彼らのカスタム「二段階自動スケーリング」ロジックです。例えるなら:
- Agones:製粉所のようなもので、絶えず「パン生地」(
ReadyPod)を生産します。 - Pod 管理サービス:パン屋の厨房のようなもので、客足を見越して事前に「パン生地」を「パン」(
AllocatedPod)に焼き上げ、カウンターに並べておきます。 - ルーティングサービス (Lambda):フロントの店員のようなもので、顧客(ユーザー)が来たら、カウンターからすぐに出来合いの「パン」を渡すので、厨房で焼くのを待つ必要がありません。
- この「Pod 管理サービス」はパン屋の店長で、カウンターのパンの数を見張り、少なくなったらすぐに厨房に催促します。これは非常に成熟し、堅牢な二段階バッファスケーリングシステムです。
スケールイン実装の詳細:「優雅な排出」(graceful draining)
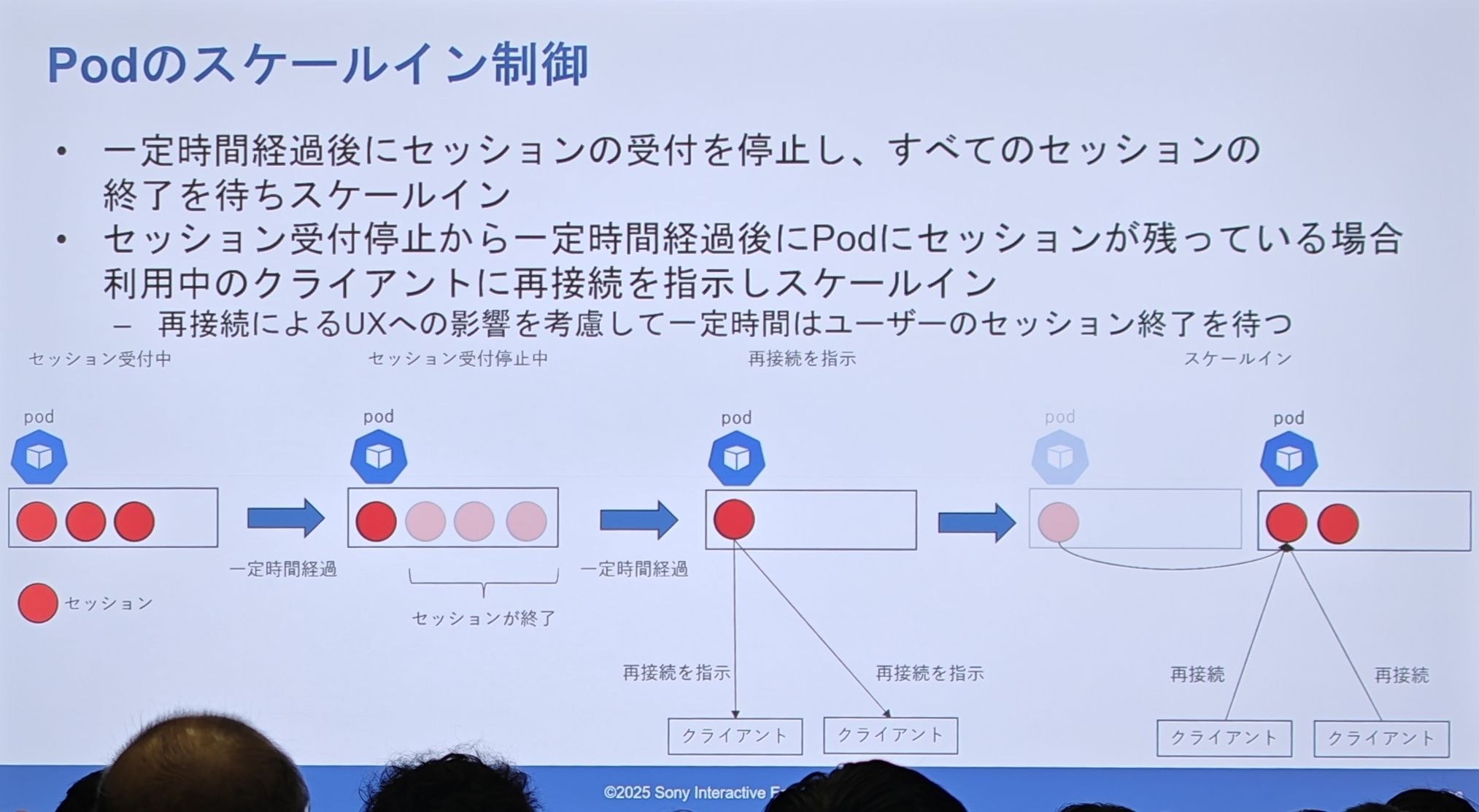
- 1つの Pod が通常通り複数のセッションを提供しています。
- システムがその Pod をスケールイン対象と決定し、Pod は「新規セッション受付停止」モードに入ります。
- 一定期間内に、一部のセッションは自然に終了し、Pod の負荷が低下します。
- タイムアウト後、まだ残っている「居座り」セッションに対して、システムは能動的に「再接続してください」という指示を出します。
- クライアントは指示を受け取ると、再度ルーティングサービスにリクエストを送り、新しく健全な Pod に割り当てられます。
- 元の Pod は完全に空になり、最終的に安全に削除されます。
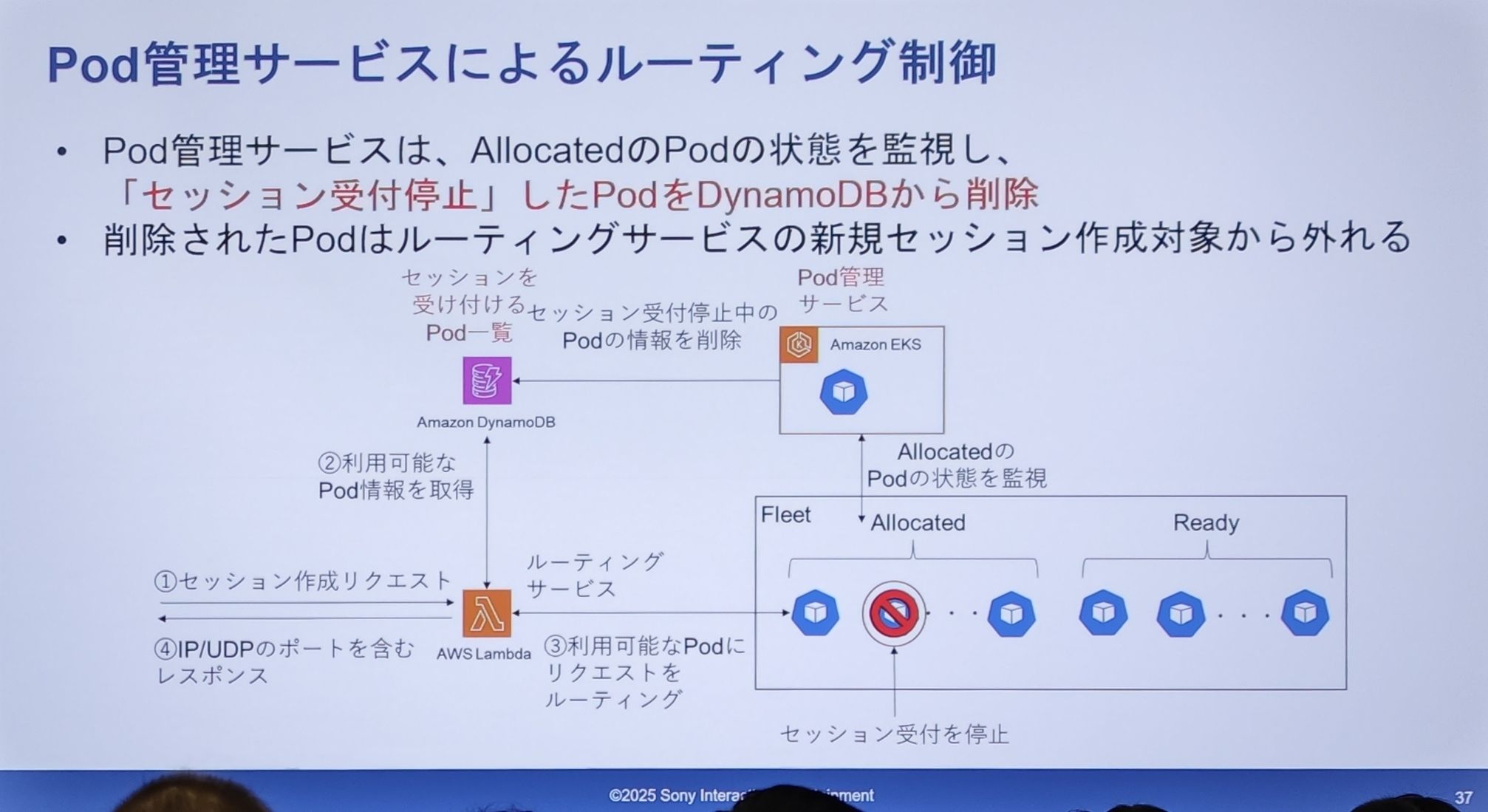
- Pod 管理サービスが
Allocated状態の Pod がセッション受付を停止する必要があると判断したとき(例えば、満杯になったり、スケールイン対象に選ばれたりした場合)、DynamoDB の利用可能リストからその Pod の情報を直接削除します。 - 情報が削除されると、ルーティングサービス(Lambda)は DynamoDB をクエリしてもその Pod を見つけられなくなり、当然、新しいセッションリクエストをその Pod に送ることはありません。
音声チャットサーバーのコンテナ化

-
ネットワーク:UDP 通信のため、
hostPort方式を使用し、Pod のポートをホスト Node 上に直接公開します。IP アドレスには、Node にアタッチされた EIP を使用します。 -
統合:Agones SDK はサイドカーコンテナとして、メインのアプリケーションコンテナと同じ Pod 内にパッケージングされます。このサイドカーが Agones コントロールプレーンと通信し、状態管理や IP/ポートの取得を行います。
-
アーキテクチャ比較:
- 左(EC2):1つの EC2 インスタンスに1つのプロセス、1つの EIP を専有。
- 右(EKS):1つの Node 上で複数の Pod を実行可能。各 Pod は「アプリケーションコンテナ + Agones サイドカー」で構成されます。これらの Pod は Node の EIP を共有しますが、異なる
hostPortで区別されます。
IP アドレス/ポートの取得方法
-
EC2 時代:インスタンスのメタデータサービスから IP を取得し、ポート番号は固定でした。
-
EKS 時代:Agones SDK Server を通じて取得します。そして、Node に固定のパブリック IP(EIP)を持たせるために、彼らは自動化スクリプトを設計しました:
- 事前に EIP プールを準備し、これらの EIP に特定のタグを付けます。
- EKS Node の起動時(K8s コンポーネントが実行される前)に、
userdataスクリプトで AWS CLI コマンドを実行します。 - このコマンドは、特定のタグを持ち、まだ使用されていない EIP を探し、それを現在の起動中の Node にアタッチします。
サービスローンチ時の課題
- 指導原則:
- サービスは絶対に中断させない。
- 既存ユーザーへの影響を最小限に抑える。
- 問題が発生した場合は、即座にロールバックできる手段を用意する。
- 切り替え後も継続的に監視し、安全を確認しながら段階的に移行する。
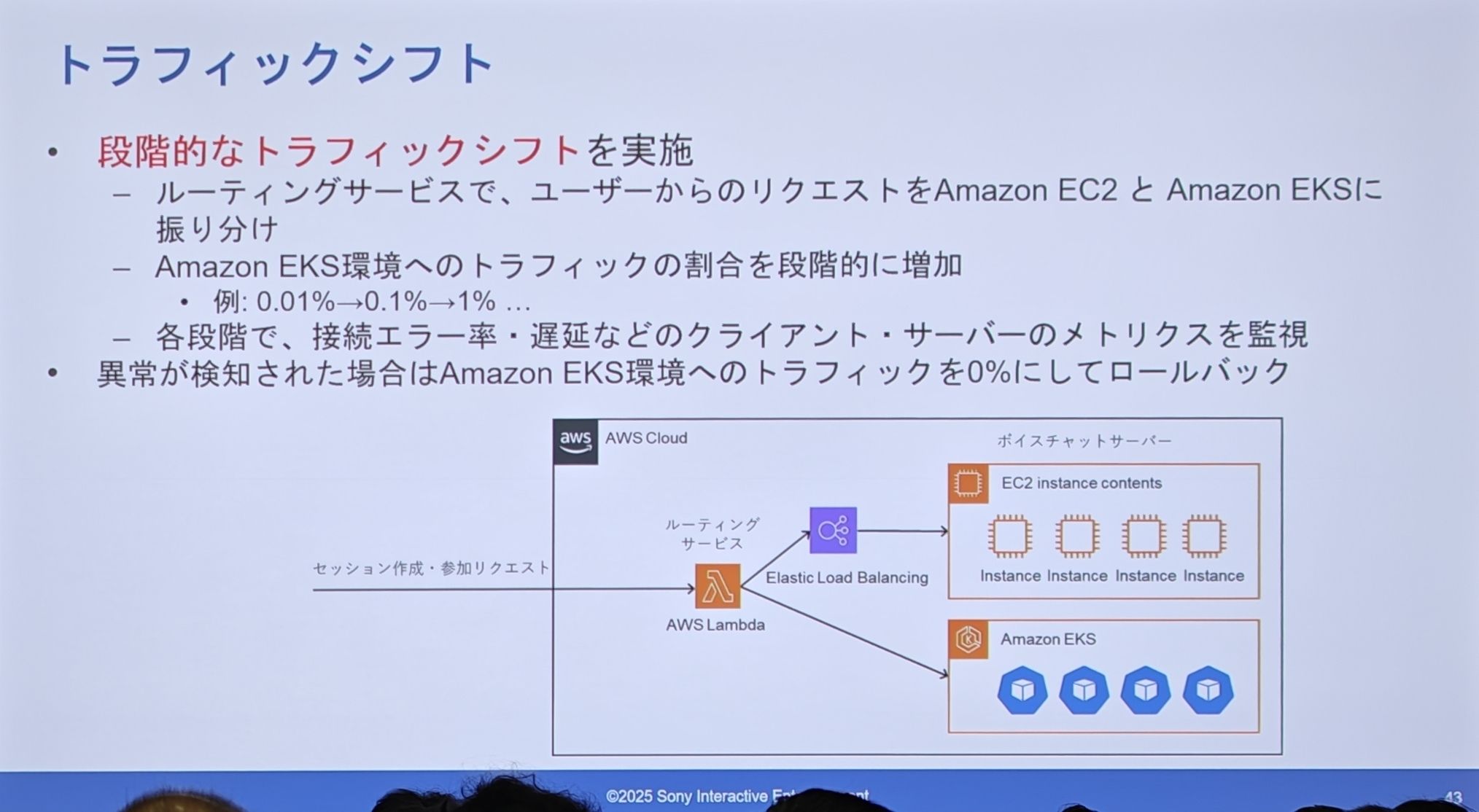
- トラフィック切り替え
- 段階的なトラフィック切り替えの実装:ルーティングサービス(Lambda)層で、ユーザーのリクエストを旧 EC2 クラスタと新 EKS クラスタに割合で振り分けます。
- トラフィック比率の段階的な増加:彼らは非常に慎重に、0.01% -> 0.1% -> 1% と少しずつトラフィックを新システムに切り替えていきました。
- 厳密な監視とワンクリックロールバック:各段階で、接続エラー率や遅延などの主要な指標を綿密に監視します。異常が発見され次第、即座に EKS へのトラフィック比率を 0% に戻し、秒単位でのロールバックを実現します。
ハイブリッドクラウド化
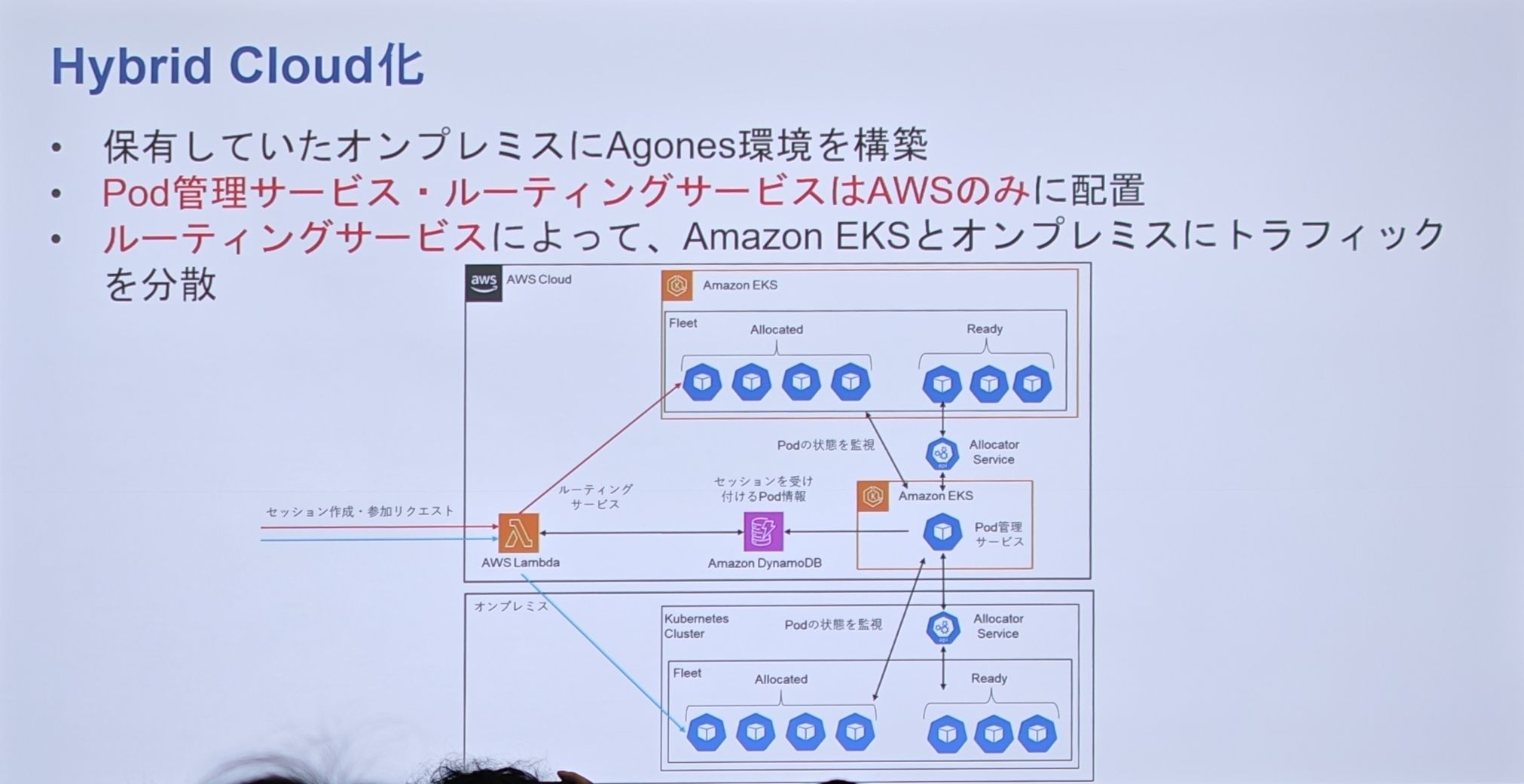
-
背景と目的:EKS への移行後、コスト最適化が次の重要な課題となりました。音声チャットは CPU 負荷の高いサービスであるため、計算コストが高額です。一方、SIE はストリーミングサービス用に世界中に自社のオンプレミスデータセンターを保有しています。そのため、彼らの最終目標は、これらのオンプレミスリソースを活用し、ハイブリッドクラウドを構築してさらなるコスト削減を図ることです。
-
ハイブリッドクラウドアーキテクチャ:
- オンプレミスデータセンター内にも、Kubernetes と Agones をベースにした環境を構築します。
- 中核となる「Pod 管理サービス」と「ルーティングサービス」はAWS クラウド上にのみデプロイし、統一された「制御の頭脳」として機能させます。
- このクラウド上の「頭脳」は、AWS EKS とオンプレミスデータセンターの K8s クラスタの両方に、トラフィックを同時に管理・スケジューリングできます。
まとめ
- WHAT:音声チャットサーバーの EKS への移行とトラフィック切り替えを紹介しました。Agones を用いてセッションの継続性、スケーリング、UDP 通信などの課題を解決し、その上で独自の「Pod 管理サービス」により「1 Pod 複数セッション」の高度なモデルと遅延の極限までの最適化を実現しました。
- HOW:段階的なトラフィック切り替えにより、ユーザーへの影響を最小限に抑えました。
- KEY RESULT:
- パフォーマンス達成:複雑なスケーリング制御を実現した後も、接続エラー率と遅延は以前の EC2 アーキテクチャと比較して「遜色ない」レベルを維持しました。
- 効率向上:他のサービスと同じ CI/CD パイプラインを利用できるようになり、チームの「認知的負荷」を軽減し、開発と運用の生産性を向上させました。