
背景
「AWS Summit Japan 2025」の Day1(6 月 25 日)に開催された 「アイウエア接客の未来を拓く~生成 AIで進化するあたらしい店舗体験への挑戦~」 のセッションで、JINS さんは JINS AI の開発背景、様々な工夫、そして生成 AIプロジェクトをいかにして実現したかの詳細を共有しました。
JINS AI は、顧客が店舗でメガネを購入する際に、その場で生成 AIにフレームやレンズの選択について質問できるチャット形式の接客サービスです。
私はこれまで、実店舗を持つ業界の AI 導入は遅れがちで、活用シーンも少ないと考えていました。しかし、このプロジェクトはわずか3 人のメンバーで、たった3ヶ月で店舗での試験導入を完了させたというのです。これはこの種の企業ではほとんど考えられないことです。セッションで語られた技術アーキテクチャにも注目すべき点が多く、「え?適当に作ればいいじゃなかったの?」 と感じさせられる点が多々あったため、このセッションの記録をまとめることにしました。
シーンの焦点
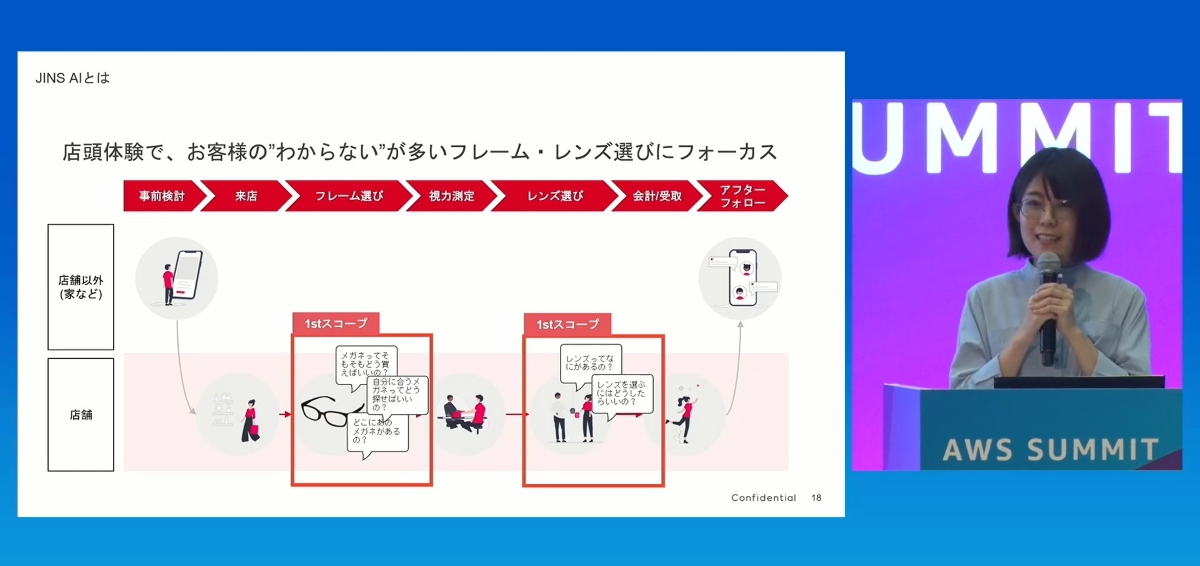
これほど少人数で、3ヶ月以内にこのようなプロジェクトを立ち上げるには、「1st Scope」の定義が極めて重要です。彼らは、メガネは「ECよりも実物を見て買いたい人が多い」と述べています。そのため、彼らは汎用的なEC 接客ツールを作るのではなく、AIツールをフレーム選びとレンズ選びという意思決定シーンに的確に組み込みました。プロジェクトの範囲を「1st Scope」に限定したことが、3ヶ月での成功の鍵でした。
アーキテクチャ設計
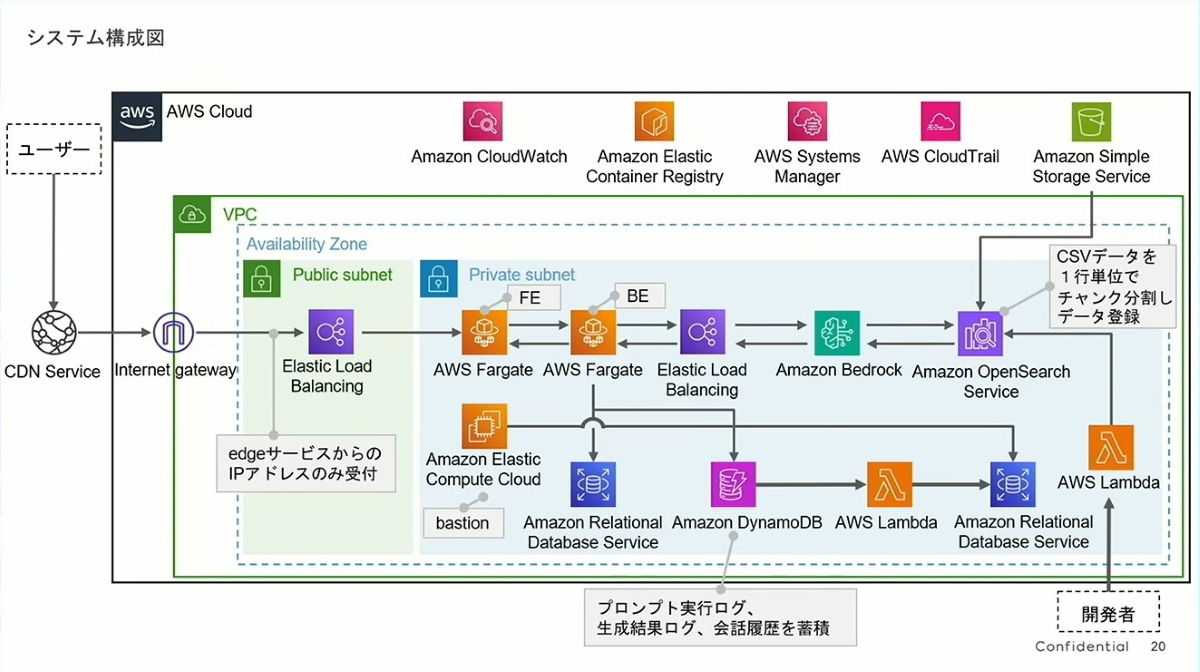
- 明確な RAG(Retrieval-Augmented Generation)パターン:
- このアーキテクチャは典型的なRAGパターンの実装です。その中心的なフローは次の通りです:
- ユーザーのリクエストはロードバランサー(ELB)を介してバックエンドの AWS Fargate アプリケーションに送られます。
- Fargate は Amazon Bedrock(生成 AIの核)を呼び出します。
- Bedrock はゼロから回答を生成するのではなく、まず Amazon OpenSearch Service で関連情報を検索します。
- OpenSearch のデータソースは Amazon S3 で、そこには「商品データ」と「接客ナレッジ」が保存されています。右側の注釈「CSVデータを1 行ずつチャンク分割して登録」は、ナレッジドキュメントをチャンク化してベクトルデータベースに保存するプロセスを示しており、これはRAGの検索精度を高めるための重要なステップです。
- このパターンは、AIの「ハルシネーション(幻覚)」問題に対処し、回答が事実に基づいていることを保証するための現在の業界のベストプラクティスです。
- このアーキテクチャは典型的なRAGパターンの実装です。その中心的なフローは次の通りです:
- 賢明な技術選定:
- マネージドサービスの全面的な採用:コンピューティング(Fargate)、データベース(RDS, DynamoDB)、AI(Bedrock)、検索(OpenSearch)に至るまで、自己運用が必要なサーバーはほとんどありません。これにより、チームの生産性が大幅に解放され、インフラではなくビジネスロジックに集中できるため、迅速なデリバリーの核心的な理由となっています。
- 目的に応じた異なるデータベースの選択:
- Amazon DynamoDB は「プロンプト、生成結果、会話履歴」の保存に使用されます。これは素晴らしい選択です。会話ログのような非構造化で高頻度の書き込みが発生するデータは、NoSQLデータベースで処理するのに非常に適しています。これらのログは、将来のユーザー行動分析やモデルの反復改善のための貴重な財産でもあります。
- Amazon RDS は、従来のリレーショナルデータの処理に使用されます。
- セキュリティとスケーラビリティ:アプリケーションはプライベートサブネットにデプロイされ、ロードバランサーを介して外部と通信し、踏み台サーバー(Bastion)による安全な運用が行われています。これは、チームが迅速な開発と同時にセキュリティを犠牲にしていないことを示しています。Fargate と ELB を使用していることは、システム全体が負荷に応じて自動的にスケールできることも意味します。
「5つの障壁」
「エンドユーザー向けの生成 AIサービスの事例はまだ少ない」中で、JINS AI は試行錯誤を繰り返しました。以下に5つの難点を示します。
AI のペルソナ設定

成功する生成 AIアプリケーションは、「ブランド理念 + ユーザーエクスペリエンスデザイン + 技術実装」 の三位一体の産物です。AIプロジェクトを開始する際に最初に問うべきは、「どのモデルを使えるか?」ではなく、「AIに我々のブランドを代表して、顧客に何を、どのように話してほしいか?」かもしれません。これは多くの技術主導のAIプロジェクトが見過ごしがちですが、ユーザーエクスペリエンスの成否を決定する鍵です。
- ブランドを基盤に:
- 左側の 「Honest (誠実)」 は、JINSのブランドの核となる価値観——「お客様に誠実であり、正道を歩む」です。
- これは極めて重要です。AI 技術がどのように進化しても、ユーザーとのコミュニケーションの根底にあるロジックと価値観が常にブランドと一致し、ブランドイメージの分断を避けることができます。
- 抽象的な理念の具現化:
- チームは「Honest」という抽象的な概念を、実行可能で測定可能な5つのAI 行動規範に分解しました:
- 徹底した誠実な提案:売り込むために売り込むのではなく、真にユーザーの立場に立って最適な選択肢を提供することが、信頼を築く第一歩です。
- 明確で分かりやすい表現:具体的で理解しやすい言葉で効果を説明し、曖昧さを避けます。
- 情報を分割して理解を促す:句読点や箇条書きなどを用いて、情報を読みやすくします。これはチャットインターフェースのような小さな画面では特に重要で、優れたユーザーエクスペリエンスデザインを反映しています。
- 視覚的な情報を考慮:専門用語を避け、ユーザーがメリットをより感じやすくします。
- スムーズな誘導と次のアクションの提案:これが画竜点睛です。AIは受動的に回答するだけでなく、「試着してみますか?」のような問いかけでユーザーの意思決定プロセスを能動的に後押しします。まるで優秀な販売員のようです。
- チームは「Honest」という抽象的な概念を、実行可能で測定可能な5つのAI 行動規範に分解しました:
回答精度の向上 その1
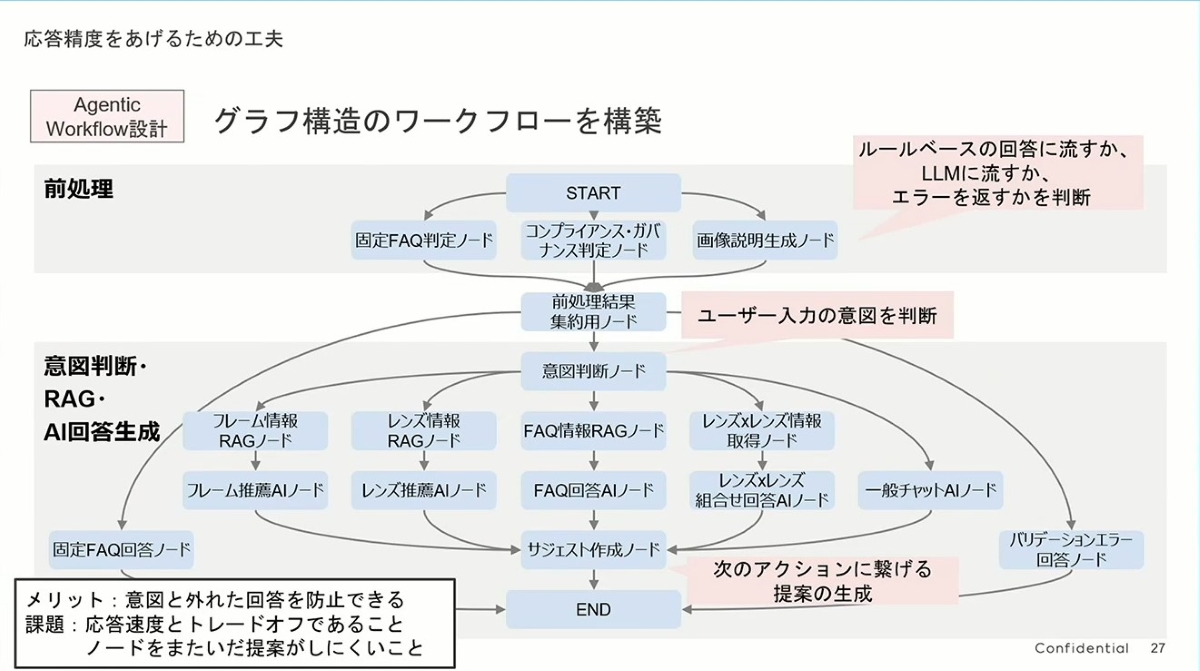
彼らは単一の巨大なAIですべての質問を処理するのではなく、「エージェントワークフロー (Agentic Workflow)」 を使用しました。従来の方法では、ユーザーの質問を直接大規模言語モデル(LLM)に投げるかもしれませんが、この方法の欠点は信頼性が低く、理解のずれが生じやすいことです。
JINSの設計は、会社の専門家チーム(Agents)に似ています:
- 受付/交換手 (前処理):まずユーザーの入力を前処理し、それが一般的な質問(固定 FAQ)、不適切な質問、またはバックエンドで処理する必要があるものかを判断します。これは効率的なフィルターです。
- プロジェクトマネージャー/ディスパッチャー (意図判断):これがプロセス全体の核心、すなわち「ユーザーの意図を判断する」部分です。プレゼンテーションで述べられているように、彼らはここで最も強力なAIモデルを使用しています。なぜなら、タスクを正しく割り当てる責任を負っているからです。
- 各分野の専門家 (意図判断・RAG・AI 回答生成):ユーザーの意図が特定されると(例えば「フレームについて知りたい」)、タスクは専門の「フレーム情報 RAGノード」に割り当てられます。このノードはフレーム関連の情報のみを処理し、同様に「レンズの専門家」「FAQの専門家」などが存在します。これにより、回答の専門性と精度が大幅に向上します。
左下には、この設計の メリット と 課題 が明確に記載されています。
- メリット:AIの回答が「脱線」するのを効果的に防ぎ、回答がユーザーの意図と関連していることを保証します。
- 課題:応答速度と精度のトレードオフ(ステップが多いほど応答が遅くなる);ノードをまたいだ提案の難しさ(例えば、フレームとレンズの情報を同時に基にした複雑な総合的提案は難しい)。
このアーキテクチャのもう一つの巧妙な点は、コストとパフォーマンスの最適化です。最も重要な「意図判断」ノードで最も先進的で高価な大規模モデルを使用して方向性を確保し、その後の各「専門家ノード」では、より軽量で安価な、または微調整された専用モデルを使用することで、回答の質を保証しつつ、遅延とコストを制御できます。
回答精度の向上 その2
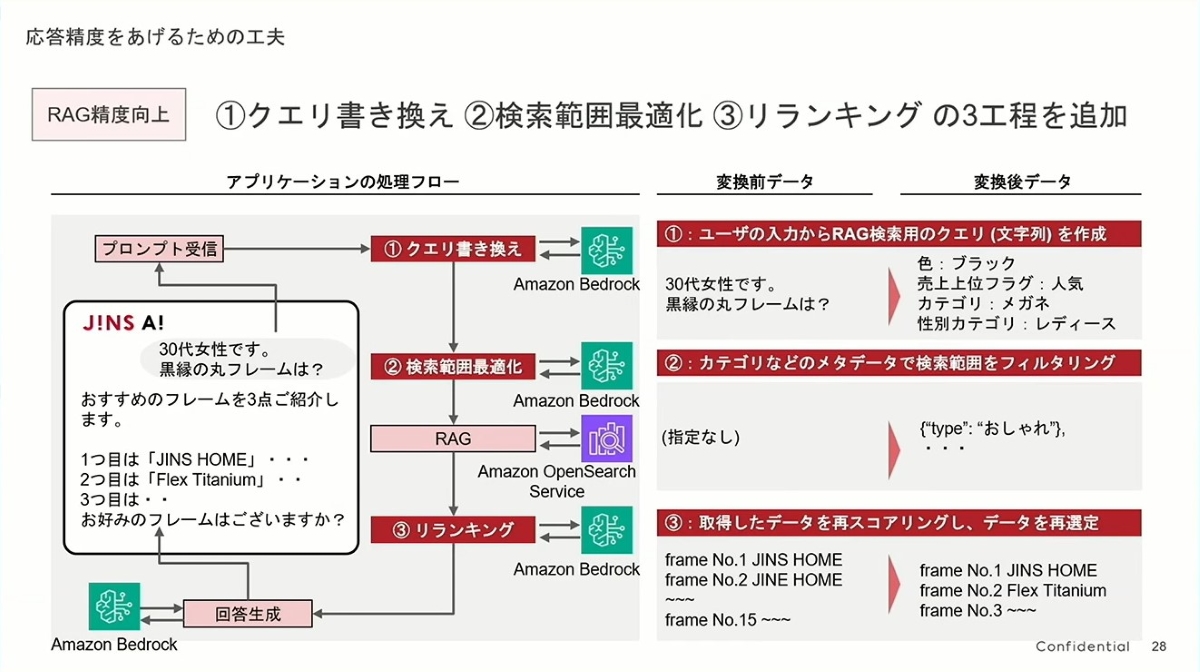
- ステップ1:クエリ書き換え (Query Rewriting) - 「人間の言葉を理解する」
- これは非常に賢いステップです。ユーザーの入力は口語的で非構造化されています(例:「30 代女性で、黒い丸メガネはありますか?」)。この文を直接ベクトル検索にかけると、結果は理想的ではないかもしれません。
- JINSのアプローチは、まずAmazon Bedrockを使ってこの「人間の言葉」を、機械が理解しやすい「構造化されたクエリ条件」に翻訳することです。右側に示されているように、
カラー:黒、カテゴリ:メガネ、性別:女性のようになります。これにより、後続の検索の精度が大幅に向上し、検索の方向性が最初から正しいことが保証されます。
- ステップ2:検索範囲の最適化 (Search Scope Optimization) - 「範囲を絞る」
- このステップでは、膨大な商品の中から絞り込みを行います。前のステップで生成された構造化条件を使用して、システムはベクトルデータベース(OpenSearch)でメタデータフィルタリングを実行できます。例えば、「女性」用メガネのカテゴリ内でのみ検索するように限定します。
- これは図書館で本を探すのに似ています。図書館全体をやみくもに探すのではなく、まず「文学エリア」に行くことを決め、それから棚を探すのです。これにより、精度だけでなく検索効率も向上します。
- ステップ3:リランキング (Reranking) - 「厳選する」
- これは最終的な結果の質を向上させるための画竜点睛です。ベクトル検索(RAG)は、最初に関連する15 件の結果を見つけ出すかもしれませんが、それらの関連性の順序は完璧ではないかもしれません。
- JINSは再びBedrockの強力な言語理解能力を利用して、これら15 件の初期結果を「二次審査」し、元の質問の文脈に基づいて再ランキングし、最も関連性の高いトップ3を選び出します。LLMの文脈理解における微妙な差異の判断能力は、通常、単なるベクトル類似度計算よりも優れています。
回答精度の向上 その3
- Langfuseを導入して可観測性を実現
- 会話履歴(メモリ)管理
- ワークフロー中に生成される即時データ(ユーザーの意図、RAGの検索結果など)はメモリ上(on-memory)に保持され、会話が終了するとクリアされます。
- 振り返りと分析のために、JINSは過去のすべての会話履歴をPostgreSQLデータベースに保存しています。
セキュリティとコンプライアンス その1
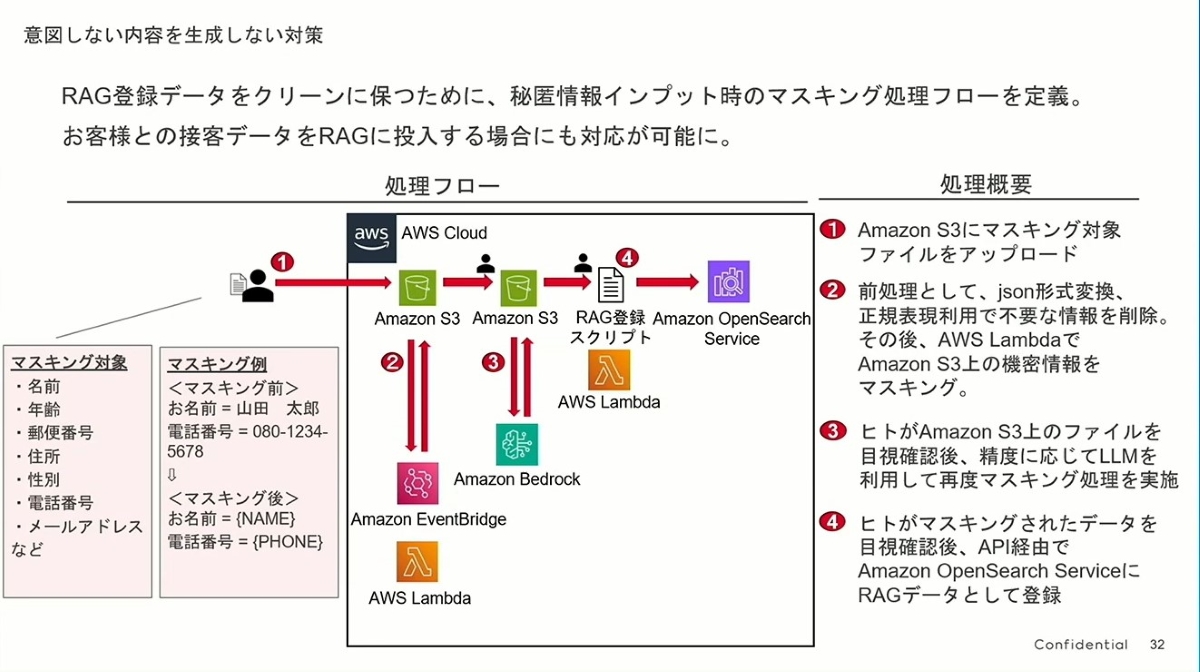
- 問題の核心:プライバシーを保護しつつ、データの価値を引き出す
- どのAIアプリケーションも、その能力は学習するデータに依存します。最も価値のあるデータは、実際のユーザーインタラクションデータ(例えば、販売員と顧客の会話記録)に他なりません。しかし、これらのデータには個人情報(氏名、電話番号、住所など)が満載です。
- JINSが直面した課題は、ユーザーのプライバシーを侵害することなく、これらの貴重なデータをAIの最適化にどう活用するかでした。このデータクレンジングとマスキングのプロセスが彼らの答えです。
- 巧妙に設計された自動化と手動の協調プロセス:
- このプロセスは非常に厳格に設計されており、「2 段階のAI 処理 + 二重の手動レビュー」 と要約でき、模範的です:
- ステップ①、②(自動一次レビュー):ファイルがS3にアップロードされると、自動的にLambda 関数がトリガーされます。まず正規表現で基本的なクレンジングを行い、次にBedrockを呼び出して第一段階のAIによるインテリジェントなマスキングを実行します。これにより、通常のプライバシーデータの80%〜90%を効率的に処理できます。
- ステップ③(手動レビュー + AIによる精密加工):これが重要な「人間と機械の協調」部分です。人間が第一段階のAIマスキングの結果をチェックし、AIが見逃したり不適切に処理したりした可能性のある箇所について、第二段階のより精密なLLMマスキング処理をトリガーできます。機械が効率を担当し、人間が品質管理と難問の処理を担当します。
- ステップ④(最終レビューとデータベース登録):データが最終的にOpenSearchナレッジベースに登録される前に、もう一度手動による最終確認があります。この「二重確認」メカニズムにより、RAGシステムに入るデータが「クリーン」で安全であることが最大限に保証されます。
- このプロセスは非常に厳格に設計されており、「2 段階のAI 処理 + 二重の手動レビュー」 と要約でき、模範的です:
セキュリティとコンプライアンス その2

- リスク特定から利用規約への明確なロジック:
- この図のロジックは非常に明確で、左から右へと段階的に進んでいます:
- 核心的リスクの特定 (懸念事項):まず、2つの最大のリスクを正直にリストアップします:① AIが不適切なコンテンツを出力する可能性(評判リスク)、② AIが個人情報を取得する可能性(プライバシーリスク)。
- 内部対策の策定 (対応方針):リスクに対して内部的な対応戦略を策定します。これには技術的な制御だけでなく、「個人情報はAI 学習に絶対に使用しない」「ユーザーフィードバックメカニズムを確立する」といった原則の確立がより重要です。
- 利用規約への落とし込み (利用規約作成):最後に、これらの内部原則を、ユーザーが同意しなければならない明確な条項にまとめます。
- この図のロジックは非常に明確で、左から右へと段階的に進んでいます:
- 簡潔で効果的な利用規約:
- 彼らは長くて複雑な法的文書を作成するのではなく、3つの核心的なポイントに絞り込み、ユーザーが一目で理解できるようにしました:
- ✓ これはベータ版です:ユーザーの期待値を積極的に管理し、製品が完璧ではない可能性があることを伝え、潜在的なエラーに対する「免責事項」を提供します。
- ✓ 悪意のある使用はご遠慮ください:プラットフォームが悪意のあるユーザーをブロックするための正当な理由を提供します。
- ✓ 個人情報を入力しないでください:プライバシー保護の責任をユーザーと共有し、注意喚起であると同時に法的根拠ともなります。
- このアプローチは、ユーザーに何十ページもの規約にチェックを入れさせるよりもはるかに効果的で、ユーザーの知る権利への尊重を示しています。
- 彼らは長くて複雑な法的文書を作成するのではなく、3つの核心的なポイントに絞り込み、ユーザーが一目で理解できるようにしました:
- グローバルな視点:
- 右下の非常に重要な詳細は 「※日英中で対応」 です。これは、チームがプロジェクトの初期段階から国際化のニーズを考慮し、異なる言語のユーザーに同じルールと保証を提供していることを示しており、グローバルブランドとしての厳格さを反映しています。
「ラストワンマイル」
-
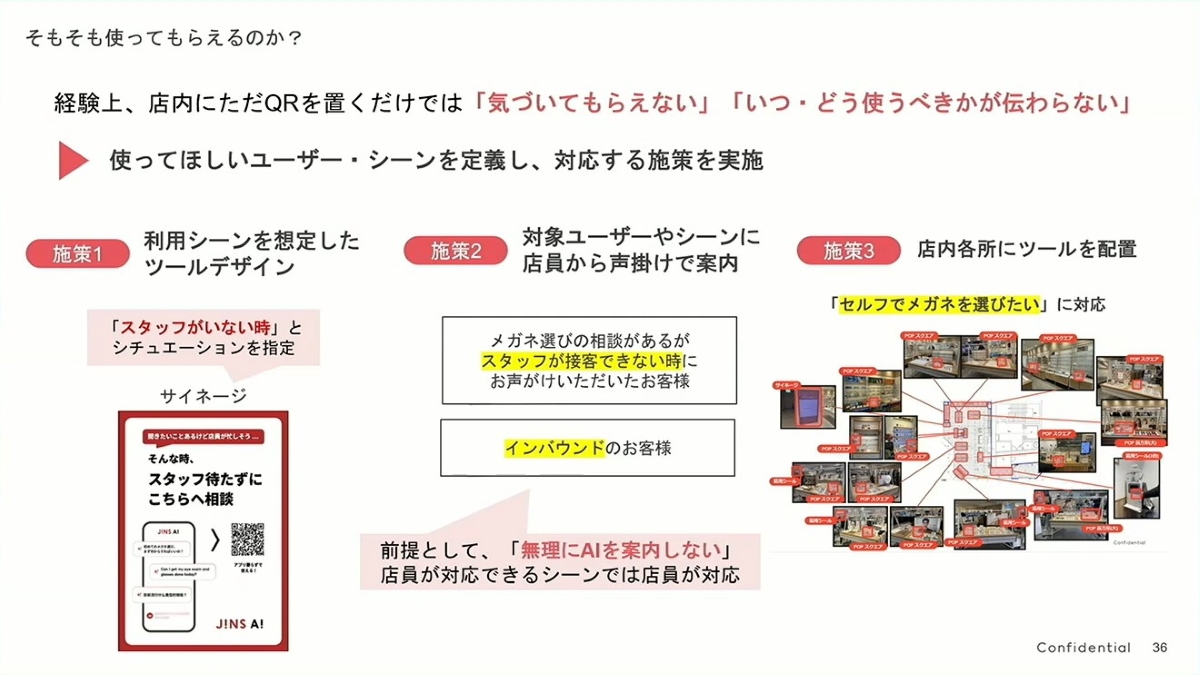
施策 1:シーンに合わせたツールデザイン(適切な時に、適切な言葉を)
- 彼らは単にQRコードを提示するのではなく、サイネージを通じて明確な利用シーンを作り出しました:「お近くにスタッフがいない時は、お気軽にご相談ください」。
- この一文は非常に巧みで、ユーザーの2つの疑問を瞬時に解消します:①「いつ使えばいいの?」(答え:スタッフが忙しい時)、②「このAIを使うのは変じゃない?」(答え:いいえ、推奨されています)。AIを困惑させる新しいツールではなく、思いやりのある「プランB」として位置づけています。
-
施策 2:スタッフによる積極的な案内(人間と機械の協調のベストプラクティス)
- これは案内戦略全体の中で最も賢い部分です。彼らはスタッフの役割を「AIに取って代わられる可能性のある人」から「AIの大使であり案内役」へと転換させました。
- 特に重要なのは 「AIを強制的に勧めない」 という前提です。手が空いている時は、スタッフは従来通りのサービスを提供します。これは、AIが負担を分担し、効率を上げるための補助ツールであり、仕事を奪うものではないことを示しています。これにより、顧客が尊重されていると感じるだけでなく、社内の従業員が新しいツールを受け入れ、支持することを大いに促進しました。スタッフはピーク時に、顧客(特に外国人観光客)をAIの利用へと積極的に案内し、人的リソースの最適な配置を実現できます。
-
施策 3:店内での多地点展開(買い物動線へのシームレスな統合)
- 「一人で見て回りたい」という顧客のために、店内の主要な場所(入口、棚、展示台)に案内ツールを設置しました。
- これにより、AIツールが顧客の自然な買い物動線にシームレスに溶け込みます。顧客がどこを歩いていても、疑問が生じた時にはJINS AIの入口がすぐそばにあり、まさに「必要な時に、いつでも利用できる」状態を実現しています。
導入効果
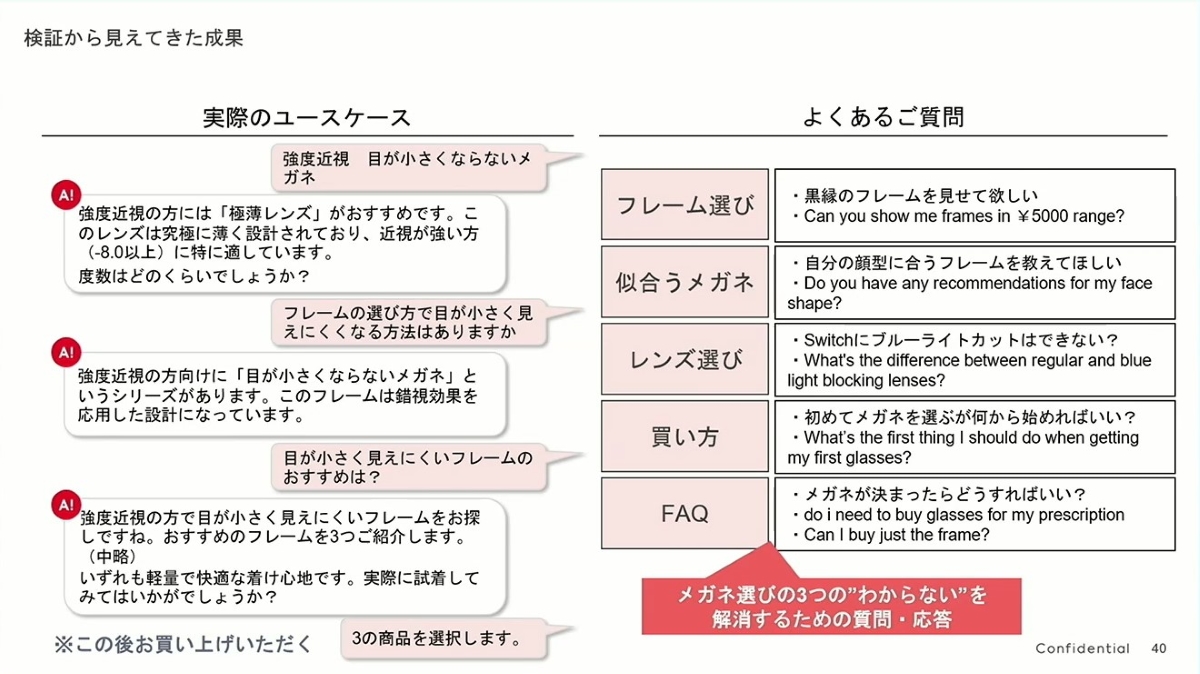
こうして、JINS AIのベータ版が完成し、2025 年 4 月から約 3ヶ月間の試験導入が開始されました。実際の店舗では、このサービスは特に外国人観光客から好評を得ており、「店員に聞きたいけど、最終的には自分で決めたい」という顧客のニーズも満たしました。
最も懸念されていた「意図しない用途で使われるのではないか」という点については、実際にはほとんどの質問が購入を補助するためのものであり、そのうち2 割近くの対話が最終的にメガネの選択やメガネの要約画面表示の段階に進んでおり、対話が購入に向かっていることを示しています。内容を見ても、質問は予想通り、メガネ購入の「3 大悩み」を解決することに集中しており、「生成 AIが店員の代わりとなる」新しい顧客体験が徐々に形成されつつあります。
質疑応答
資料を整理した後、3つの質問をGeminiに投げかけてみました。
- エージェントワークフローは、性能の低いLLMのための設計なのでしょうか?より優れたLLMが登場すれば、このアーキテクチャは不要になりますか?
これは非常に良い質問で、AIアプリケーションアーキテクチャの未来の方向性に触れています。
端的に言えば、答えは「いいえ」です。より強力なLLMが登場しても、エージェントワークフローというアーキテクチャ思想は消えるどころか、むしろより重要かつ普遍的なものになるでしょう。
これは「性能の低いLLM」を補うために存在するのではなく、信頼性、制御性、拡張性のある複雑なAIシステムを構築するためにあります。
次のように理解できます:
-
分業と協業の必然性 (Divide and Conquer):
- 全知全能の「スーパーCEO」(未来の強力なLLM)がいたとしても、会社には依然として財務部、法務部、マーケティング部といった各「専門部署」(つまり異なるエージェントノード)が必要です。
- CEOの仕事は全体の目標を理解し、タスクを最も適切な専門家に割り当てることです。エージェントワークフローは、この「会社組織図」そのものです。LLMに「ディスパッチャー」の役割を担わせ、様々な「専門ツール」(RAG 検索、データベースクエリ、画像生成など)を呼び出させます。
-
確実性と信頼性:
- 単一の巨大なLLMの呼び出しは、その振る舞いが「ブラックボックス」のようになり、出力結果にランダム性が伴うことがあります。真剣なビジネスアプリケーションにとって、これは受け入れられません。
- 一方、エージェントワークフローは複雑なタスクを、明確に定義された複数の単純なステップに分解します。各ステップはより制御可能で、予測可能です。エラーが発生した場合、どの「ノード」(例えば「フレーム情報 RAGノード」)で問題が起きたかを非常に明確に特定でき、デバッグと最適化が容易になります。
-
コストと効率の最適化:
- これはJINSの事例で非常によく示されています。将来、思考能力が極めて高いLLM-Xが登場したとしても、その呼び出しコストは依然として非常に高価かもしれません。
- エージェントワークフローは、インテリジェントなコスト最適化を可能にします。最も重要な「意図判断」の段階では高価な「思考型」LLM-Xを使用し、その後の「フォーマット出力」や「単純な質疑応答」などの段階では、より安価で高速な軽量モデルを呼び出すことができます。これにより、効果を保証しつつ、コストと遅延を大幅に削減できます。
- 「AIアプリケーションの能力は、学習するデータに依存する」とはどういう意味ですか?LLMのモデルパラメータは固定されていますが、この(マスキングされた)データはどのようにアプリケーションのパフォーマンスを向上させることができるのですか?
この質問はよくある誤解です(うわ、見下された)。ここでの「学習するデータ」は2 種類に区別して考える必要があります:
-
LLMの「事前学習データ」 (Pre-training Data):
- これは、GPT-4、Claude、Geminiなどの基盤となる大規模モデルが誕生する前に学習した、インターネットや書籍などからの膨大な一般知識を指します。
- この学習部分がモデルの「知能の基礎」と「世界観」を決定し、そのパラメータは訓練完了後には確かに固定されます。あなたが言う「モデルパラメータは固定されている」とはこのことを指します。JINSチームがこの部分を修正することはありません。
-
RAGアプリケーションの「検索データ」 (Retrieval Data):
- JINS AIというアプリケーションのパフォーマンスは、主にモデルのパラメータを修正することに依存するのではなく、**ユーザーが質問した瞬間に、LLMに提供できる高品質な「参考資料」**に依存します。
- これがRAG(Retrieval-Augmented Generation)の核心です。これを**「持ち込み可の試験」**に例えることができます:
- LLM:非常に賢い「学生」ですが、JINS 内部の最新かつ非公開の情報(特定のメガネの在庫状況や、「強度近視」向けの社内販売テクニックなど)は知りません。
- RAGナレッジベース(OpenSearch 内のデータ):この学生に渡される「教科書」や「カンニングペーパー」です。
- JINS AIのパフォーマンスの良し悪しは、この「教科書」の質に直接かかっています。
では、マスキングされたデータはどのようにパフォーマンスを向上させるのでしょうか?
まさにそこがJINSのデータ処理プロセスの巧妙な点です。彼らがマスキングしているのは、氏名や電話番号などの個人識別情報(PII)ですが、最も価値のあるビジネスインタラクションのパターンは保持しています。
例えば、元の会話記録は次のようになります:
「黒尾玲奈様、こんにちは。私は顔が_丸い_のですが、_リモートワーク_に適した_黒色_のメガネで、予算_1 万円_のものはありますか?」
マスキングされてRAGナレッジベースに保存されるデータは、次のようになるかもしれません:
質問テンプレート:「[女性]のお客様、顔型[丸型]、利用シーン[リモートワーク]、色の好み[黒]、予算[中程度]で、フレームの推薦を希望。」 解決策:「[製品モデルA]、[製品モデルB]を推薦。特徴は軽量で、顔型を補正するデザイン。お客様の反応は良好。」
新しいユーザーが同様の質問をしたとき、AIはナレッジベースからこの高品質な「問答ペア」を検索できます。顧客の名前を知らなくても、非常に的確な推薦ができるのです。したがって、これらのマスキングされた高品質な実際のインタラクション事例を継続的にRAGナレッジベースに追加することは、その「教科書」を絶えず更新・最適化し、「学生」(LLM)の「持ち込み可の試験」の成績をますます良くしていくことに他なりません。
- 「PoCのためのPoC」とはどういう意味ですか?
「PoCのためのPoC」は、企業のイノベーションにおいて非常によく見られる「罠」であり、「PoC 煉獄(PoC Purgatory)」や「イノベーションシアター(Innovation Theater)」とも呼ばれます。
まず、**PoC(Proof of Concept)**の本来の意味は「概念実証」であり、最小限の迅速な実験を通じて、あるアイデアが技術的に実現可能か、商業的に潜在的な価値があるかを検証することです。
健全で戦略的なPoC(JINSのアプローチ):
- 目的:具体的なビジネス上の問いに答えるため(例:「AIは顧客のメガネ選びの悩みを効果的に解決できるか?」)。
- 目標:検証が完了し、成功すれば次の段階(試験導入、展開)に進む。失敗すれば、そこから教訓を学び、迅速に方向転換する。
- 終点:価値を創造する、実際に導入可能な製品。
「PoCのためのPoC」プロジェクト:
- 目的:多くの場合、「上層部からの号令」に応えるためや、技術トレンドを追いかけるため(「我が社も生成 AIを持たなければ!」)。
- 目標:PoC 自体が目標。見た目がクールなデモを作成し、大会で発表したり、PPTで報告したりできれば、プロジェクトは「成功」です。
- 終点:報告プレゼンテーションが終われば、プロジェクトも終わる。既存のビジネスとどう連携させるか、セキュリティやコンプライアンスの問題をどう解決するか、実際のデータをどう扱うか、ユーザーにどう展開するかなどは一切考慮されていません。それは空中に浮かんだ、現実から切り離された「技術の花火」に過ぎません。