
背景
カプコンさんの「モンスターハンター:ワイルズ」は、発売からわずか 1 ヶ月で全世界累計販売本数が 1000 万本を突破しました。シリーズで初めて「クロスプラットフォームプレイ」に対応した本作は、リリース時に数百万の同時接続を達成しました。プレイヤーの実際の感想はどうだったのでしょうか?
体験版から正式リリースに至るまで、多くの声は PC 版の最適化不足、コンテンツの薄さ、アップデートの遅さに集中していましたが、オンラインマルチプレイの体験については肯定的な評価が得られました。
オンライン体験は非常に良い。VPN も不要で、クロスプラットフォームも安定している。
知名度の高い IP である「モンスターハンター」への好奇心から、私は「AWS Summit Japan 2025」の 2 日目(6 月 26 日)に開催された 「モンスターハンターワイルズ 100 万以上のユーザー同時接続を支えたネットワークアーキテクチャ」 というセッションに参加し、エンジニアである筑紫啓雄氏から、「クロスプラットフォーム」ゲームサーバーを構築する過程での技術選定、独自の革新的なアイデア、そして様々な挑戦について直接お話を伺いました。
核心的な課題
モンスターハンターシリーズ過去作の制約:プラットフォームホルダー(PlayStation, Steam など)それぞれの独立したネットワークサービスへの依存により、プレイヤーはプラットフォームを越えて一緒にプレイすることができませんでした。本作で待望された新しい目標の下では、当然ながらシリーズで従来使用されてきたプラットフォームホルダーのネットワークサービスでは実現不可能です。この壁を打ち破るため、開発チームは自ら、ゼロから独自のネットワークバックエンドサービスを構築する必要がありました。このビジネス上の決定が、その後のすべての複雑な技術選定の根本的な出発点となりました。
アーキテクチャ
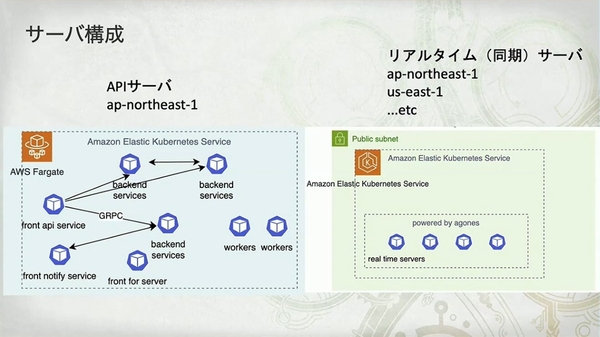
- API サーバー: 単一リージョン(
ap-northeast-1、すなわち東京)にデプロイされ、ゲームのコアロジックとデータを処理します。 - リアルタイムサーバー: グローバルに分散配置され、プレイヤー間の位置やアクションなど、低遅延での同期が必要な情報を専門に処理します。
- 技術スタックの選定:
Amazon EKSonAWS Fargate - 通信方式: フロントの API サービスは HTTP リクエストを受け付け、バックエンドのサービス間は
gRPCで効率的に通信します。
Amazon EKS on AWS Fargate の最大のメリットは、ノード管理が不要で、運用負荷を大幅に軽減できることです。しかし、代償も明確です。「サーバ (pod) の立ち上がりは遅い (1 分くらい)」そして「DaemonSet は使えない」。
マイクロサービスアーキテクチャは、複雑性の高いプロジェクトにおいてチームのアジリティを維持するのに確かに役立ちました。マイクロサービスの利便性を享受するには、その固有の管理と設計の複雑性を克服することが代償として必要です。
- 良かったところ:
- 「エラーや遅延の特定が容易」
- 「各担当者がコンフリクトなく開発可能」
- 「特定のサービスに対して独立したホットフィックスが可能」
- 難しいポイント:
- 「CI/CD の複雑化」
- 「データ操作のトランザクション処理」
App Mesh から VPC Lattice へ

チームは当初、手間を省くために AWS マネージドの App Mesh を選択しました。この図は、古典的なサービスメッシュの「サイドカー」モデルを示しています。アプリケーション(App)のトラフィックは、同じ Pod 内の Envoy プロキシにインターセプトされ、Envoy プロキシ間で通信が行われます。
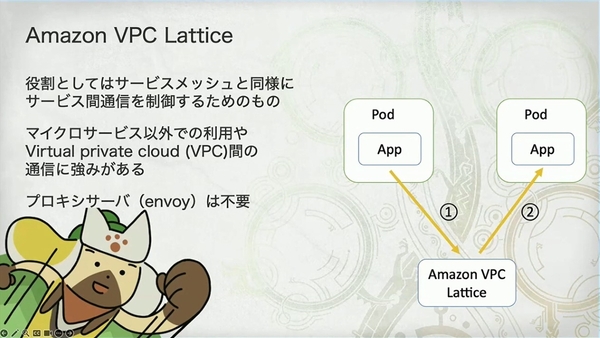
しかし、『モンスターハンター:ワイルズ』のオープンベータテスト(2024 年 10 月)直前に、App Mesh がサービス終了を発表(終了日は 2026 年 9 月 30 日)。チームは急遽、代替案への切り替えを余儀なくされました。この図は、代替案である VPC Lattice のアーキテクチャを示しています。最も核心的な違いは、Envoy プロキシが不要で、アプリケーションが直接 VPC Lattice サービスと通信する点です。
移行後のアーキテクチャ
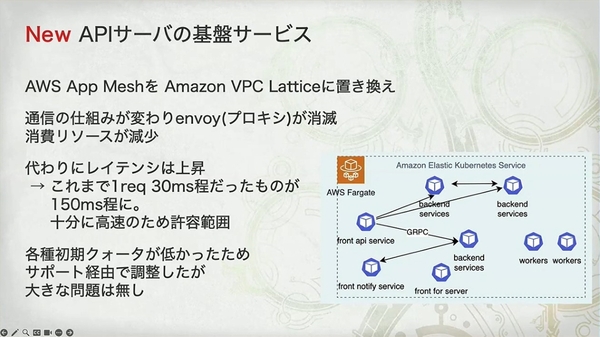
- リソースの節約:
- VPC Lattice は Envoy サイドカーが不要なため、その分の Pod のリソースが節約されます(「その分の pod のリソースが浮く」)。
- 遅延の増加:
- 通信パスが「アプリケーション -> ローカルプロキシ -> ターゲットプロキシ -> ターゲットアプリケーション」から「アプリケーション -> VPC Lattice サービス -> ターゲットアプリケーション」に変わりました。
- トラフィックが外部のマネージドサービスを迂回するため、遅延が 30ms から 150ms に増加した理由が説明できます。
チームは製品ローンチ直前まで「賭け」に出るのではなく、2 回のオープンベータテスト(OBT1 と OBT2)の間に、明確な移行と再テストの計画を立てました。
- 得られたもの:
- Envoy プロキシを排除し、リソース消費を削減。
- 失ったもの:
- 遅延が 30ms から 150ms に増加。
「十分に高速のため許容範囲」という結論は、これが熟慮の末の成功した技術的なトレードオフであったことを示しています。
「集会所」サーバー
核心的なタスクと課題
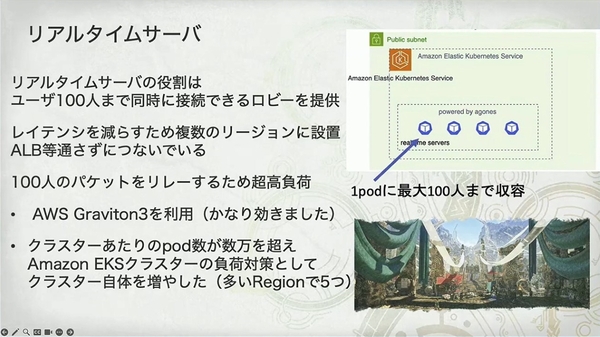
- 機能: 最大100 人が同時にオンラインになる「ロビー(集会所)」を提供。
- 特徴: 100 人分のデータパケットを中継する必要があり、文字通りの 「超高負荷」。
- アーキテクチャ戦略:
- グローバル展開、ALB のバイパス: 極限の低遅延を実現するため、サーバーは複数のリージョンに展開され、クライアントは遅延を増加させるロードバランサーをバイパスして直接接続します。
- ハードウェアの最適化: AWS Graviton3 プロセッサを名指しで賞賛し、「かなり効きました」という高い評価を添えて、Arm アーキテクチャプロセッサがネットワーク集約型アプリケーションで高い性能を発揮することを証明しました。
- クラスターの水平スケール: 単一の EKS クラスターの Pod 数が数万に達し、コントロールプレーンが耐えきれなくなった際、彼らは非常に高度な手法——クラスター自体の数を増やす(「多い Region で 5 つ」)——を採用し、単一リージョン内で複数の EKS クラスターを運用して負荷を分散させました。
独自のスケール戦略
- チームは従来の「CPU/メモリベース」のスケーリングモデルを捨て、「人数や条件(例:「初心者部屋」、「上級者部屋」)に応じて制御する」 という戦略を採用しました。
- その理由はスライドでも説明されています:「ユーザの動きや接続数によって消費リソースが大きく変わる」。例えば、100 人全員が激しく戦闘している部屋のリソース消費は、100 人全員が放置している部屋よりもはるかに高くなります。CPU だけを見ても、真の需要を正確に反映することはできません。
- 技術的実装: 彼らはスケーラーとして Karpenter を使用しました。Karpenter の「ジャストインタイム」なノードプロビジョニング能力は、このようなビジネスロジックに基づいたきめ細やかなスケーリング要件と完璧に合致しました。
エピソード
「Graviton3 ベースの C7g インスタンスで運用していたが、リージョンのインスタンスを使い切ってしまったことがあった。一時期、本番環境では 30 万 pod ほどを使っていた」
「モンスターハンター:ワイルズ」のローンチ時の負荷は想像を絶するレベルに達し、AWS のあるリージョンの特定タイプ(C7g)のサーバー在庫をすべて使い果たしてしまいました。
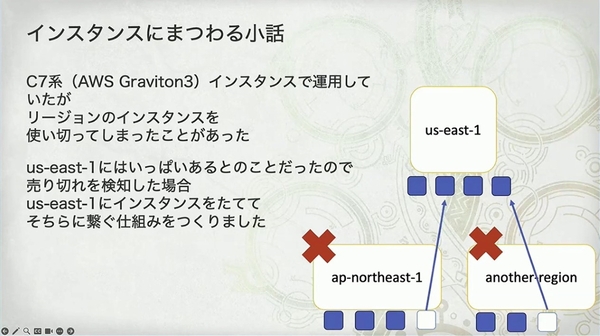
彼らの解決策は、自動フェイルオーバーメカニズムの構築でした。優先リージョンのインスタンスが「売り切れ」を検知すると、システムは自動的に容量がより豊富な us-east-1(米国東部 1)リージョンに切り替えてサーバーを作成します。(それで大丈夫なのか?そのネットワーク遅延ではプレイヤーから苦情が殺到するのでは?)
データベースの選定

- データベース選定の指針:「超高トラフィック」に耐えうること、そしてユーザー数が未知の状況で容易にスケールできること。
- スライドは 2 つの主要な選択肢を明確に示しています:NewSQL(リレーショナルデータベースの ACID 特性と高いスケーラビリティを両立)とNoSQL(柔軟なスキーマ、優れたパフォーマンス)。
- 最も重要な決定は右下の文言です:「モンスターハンターワイルズでは NewSQL, NoSQL 両方を使いました」。
メインデータベース:DynamoDB
- なぜDynamoDBをメインデータベースとして選んだのか。その理由は非常に典型的かつ正当です:データアクセスの大部分は、単一ユーザーに対する高頻度のキーバリュークエリ、例えば「自分のフレンドリストを取得する」「クエスト履歴を照会する」などです。これは DynamoDB が最も得意とする領域です。
- スライドは非常に興味深い方法(自問自答:「複雑な検索は必要か?」→「必要だ!」)で DynamoDB の弱点を引き出し、第二のデータベース導入への伏線を張っています。
複雑な検索の難題:「救難信号」

- プレイヤーは「プレイスタイル」「強さ」「言語」など複数の次元で参加可能なゲームルームを絞り込み、検索する必要があります。
- データベースのパフォーマンスにとって「かなりきついデータ条件」である「救難信号」検索機能。数百万のプレイヤーが作成した数千万の動的なクエストの中から、このような多条件の組み合わせクエリを効率的に実行することは、単一のキーバリューデータベース(DynamoDB など)では困難です。
これは単純なクエリではありません:
- 条件の組み合わせ: 「システムが自動で決定する条件(モンスター、マップなど)」と「プレイヤーが自身で設定する条件(参加人数、パスワードの有無など)」から構成されます。
- 多次元かつ低カーディナリティのクエリ: プレイヤーは検索時に、モンスター、クエストタイプ、難易度、言語など複数の次元で絞り込みができます。これらの条件の多く(プラットフォーム、言語など)はユニークな値が少なく、「カーディナリティが低い」ため、キーバリューデータベースのインデックス設計にとって大きな課題となります。
なぜ TiDB なのか?

開発初期には Amazon Aurora Serverless v2 を試しましたが、その 「最大性能」 とアプリケーション層での 「水平分散の複雑さ」 を考慮し、最終的に TiDB に切り替えました。これは、チームが単に「使える」だけでなく、極限の負荷下でも確実にスケールできる「切り札」を必要としていたことを示しています。
- メリット:
- メンテナンスウィンドウなし、無停止でのスペック変更、アプリケーションに対して透過的な水平スケーリング。これらは 24 時間 365 日稼働するゲームにとって極めて重要です。
- デメリット:
- 内部の多層アーキテクチャによる若干の速度低下、ホットスポット発生時のパフォーマンスへの影響。
CQRS(コマンド・クエリ責務分離)
データフロー:
- プレイヤーが「救難信号」検索を開始すると、リクエストは TiDB に送られます。
- TiDB はその SQL エンジンを利用し、特別に最適化された「検索用テーブル」で効率的に多条件フィルタリングを行い、条件に合うクエスト ID のリストを返します。
- アプリケーションは ID リストを受け取った後、Amazon DynamoDB で最も効率的なバッチキーバリュークエリを実行し、クエストの詳細情報(メンバー、ステータスなど)を取得します。
核心的な利点:
- 責務の分離: TiDB に得意な複雑なクエリを専門にさせ、DynamoDB に得意な高並行キーバリュー読み書きを専門にさせます。
- パフォーマンスの分離: 高負荷なクエリトラフィックを通常の読み書きトラフィックから分離し、相互の影響を避けます。
- コストと効率の最適化: TiDB には必要なインデックスデータのみを保存することで、NewSQL データベースのストレージコストとデータ量を大幅に削減し、クエリパフォーマンスを確保します。
DynamoDB で 80% の定型的で高並行なキーバリュークエリを処理し、その極限のパフォーマンスとスケーラビリティを発揮させます。
TiDB で 20% の「難題」——すなわち「救難信号」のような複雑な多条件検索——を解決します。彼らは検索用のインデックスデータのみを TiDB に格納し、ターゲット ID をクエリで取得した後、DynamoDB に戻って完全な情報を取得します。これは非常に古典的で効率的な CQRS(コマンド・クエリ責務分離)の実装パターンです。
エンドツーエンドの可観測性
Prometheus+Grafana
- 技術スタック: チームは Amazon Managed Service for Prometheus と Amazon Managed Grafana を選択しました。
- 核心的な動機: 再び実用的な哲学が表れています。自前で Prometheus を構築するのは「かなりのメモリ食い」で管理が面倒であり、そのクエリ言語 PromQL を学ぶのも「かなり大変」。AWS のマネージドサービスを採用することで、チームは貴重なエネルギーをインフラ運用から解放し、ビジネスそのものに集中しました。
APM によるマイクロサービスの洞察

- なぜ APM が必要か: マイクロサービスアーキテクチャを採用したため、分散トレーシングが必須でした。
- 技術選定: 自前での Jaeger 構築と AWS X-Ray の間で、チームは再び「楽に構築できそうな」AWS X-Rayを選択しました。
- 価値:
- 図に示されている X-Ray のサービスマップは、もともと複雑に絡み合っていたマイクロサービスの呼び出し関係を、一目でわかる明確なトポロジー図に変えました。開発者はリクエストがクライアントから各サービスをどのように流れていくか、そして各ステップの遅延を直感的に見ることができます。
- 4 枚目の図は、APM のミクロな洞察力を示しています。これはリクエストの「ウォーターフォール」トレース詳細で、
dynamodb.Getやmomento.SetNXWithTTL(ここでは彼らが Momento をキャッシュサービスとして利用していることも明かされています)といった下流の呼び出しの正確な所要時間を見ることができます。問題が発生した際(図の赤い感嘆符のように)、開発者は具体的なコード行やエラーのスタックトレースを迅速に特定できます。
極限負荷テスト
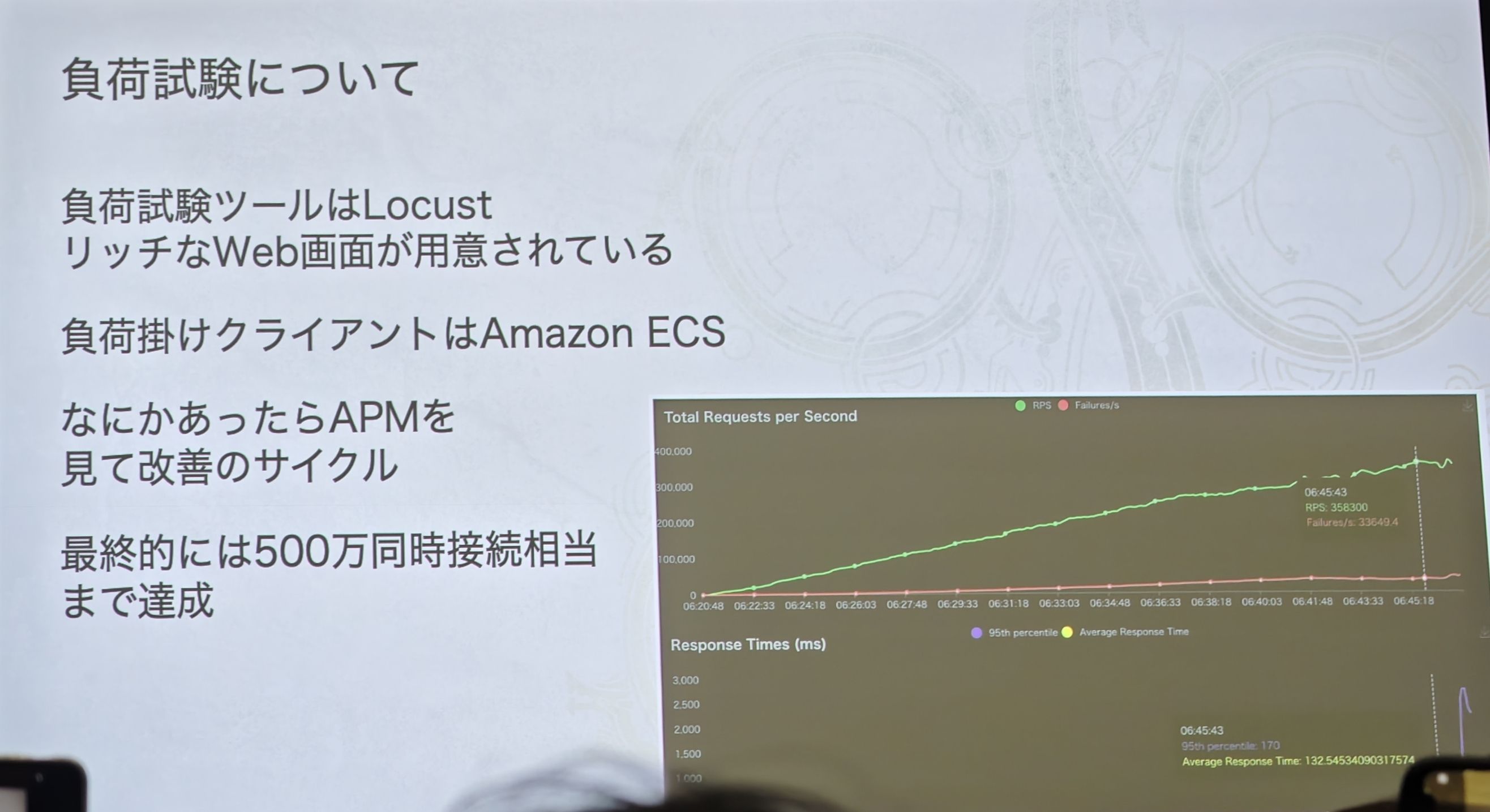
- テスト方法:
- ツール: 豊富な Web インターフェースを持つ Locust を使用。
- 負荷テストクライアント: Amazon ECS を使用。プレゼンテーションで述べられているように、これにより Graviton プロセッサとスポットインスタンスを活用してテストコストを大幅に削減できます。
- 改善サイクル: スライドは彼らの作業モデル——**「負荷テストで問題を発見 -> APM でボトルネックを特定 -> 改善を行う」**というクローズドループ——を明確に示しています。
- 最終成果: グラフの緑色の線は着実に上昇し、最終的に驚異的な数字——「500 万同時接続相当まで達成」——に達しました。この数字は、これまで議論してきたすべてのアーキテクチャ設計——マイクロサービス、サービスメッシュから、リアルタイムサーバー、ハイブリッドデータベースまで——の最終的な価値を体現しています。
ローンチ成功の保証:AWS Countdown Premium

- 重要な役割: このサービスは、オープンベータテストや正式リリースなどの重要な局面で、緊急対応サポートを提供しました。
- 実例: スライドでは非常に具体的な例が挙げられています——「監視のクォータが一部引っかかった」。トラフィックのピーク時には、これは致命的になり得ます。
- 解決策: チームが事前にAWS Countdown チームとアーキテクチャやリソース計画を共有していたため、問題が発生した当日に、AWS は迅速かつスムーズにクォータを引き上げることができました。これは、「積極的なコミュニケーションと事前の計画」が超大規模イベントへの対応においていかに重要であるかを十分に示しており、潜在的な危機を未然に防ぎました。
- もちろん、ここには宣伝の意図もあるかもしれません(笑)。
振り返り
- 最大の課題は依然としてAWS の様々なリソースクォータであり、Countdown サービスの重要性を改めて裏付けています。
- 技術的に最も厄介だったのは、やはり 「救難信号検索」 機能でした。
- 当初、リアルタイムサーバーの技術スタック(EKS)と一貫性を保つため、API サーバーには Amazon EKS on Fargate を選択しました。
- 残念な点: Amazon ECS の方がコスト面で優位でした。ECS はスポットインスタンスとGraviton プロセッサという 2 大「コスト削減の切り札」をより柔軟に活用できますが、当時の EKS Fargate ではそれが制限されていました。
チーム
- プログラミング言語: チームは Go 言語で統一。
- チーム規模: わずか 8 人!この精鋭チームが、数百万のプレイヤーが同時にオンラインになる巨大なバックエンドサービスを構築・運用しました。これは奇跡とも言え、クラウドネイティブなマネージドサービスと自動化ツールが「人的効率」をいかに向上させるかを裏付けています。
- 働き方: 「基本的には横断で対応」。これは、彼らが高度に協調的なクロスファンクショナルチームであることを示しています。
質疑応答
個人的な経験では、オンプレミスの Prometheus を構築するのはそれほど面倒ではありません。むしろ、Kubernetes エコシステムの中では比較的簡単な部分だと感じています。kube-state-metrics を改造して、クラスターがより多くのメトリクスをサポートできるようにしたこともあります。
おっしゃる通りです。中規模または通常の Kubernetes クラスター、あるいは大規模でもビジネスが比較的単一なクラスターの場合、prometheus-operator などのツールをベースに自前で Prometheus 監視システムを構築するのは、成熟した、それほど面倒ではない解決策です。あなたのように kube-state-metrics を改造する能力のある経験豊富なエンジニアにとっては、この部分は制御可能だと感じるでしょう。
しかし、カプコンがここで言う「面倒」や「メモリ消費」は、彼らの前例のない規模と極度に動的な環境と合わせて理解する必要があると思います。
a) 規模の「桁」の違い:
プレゼンテーションでは「ある時期、本番環境で約 30 万の Pod を使用していた」と述べられています。30 万の Pod、数万のノード(Karpenter によって動的に作成)、そしてその背後にある EKS コントロールプレーン、ネットワークコンポーネント、ストレージなどが、天文学的な数の時系列データ(Time Series)を生成します。
時系列データの数(カーディナリティ)が数千万、さらには億のレベルに達すると、Prometheus のメモリ消費は急激に膨れ上がり、単一の Prometheus インスタンスではもはや対応できません。その場合、自前で構築するには Thanos、Cortex、Mimir といったフェデレーションクラスターソリューションを導入して、シャーディングや長期保存を行う必要があります。そして、高可用性を持つ Thanos クラスターを維持し、そのストレージ、圧縮、クエリゲートウェイなどのコンポーネントを管理する複雑さは、単一の Prometheus をはるかに超え、どのチームにとっても大きな運用負担となります。
b) ビジネスの「動的」性:
ゲームサーバーは極めて動的です。Karpenter はプレイヤーの「集会所」の需要に応じて、数分以内に数百、数千のノードや Pod を作成・破棄します。このような激しい変動は、サービスディスカバリやメトリクス収集にとって大きな試練であり、同時にライフサイクルが非常に短い時系列データを大量に生み出し、高カーディナリティ問題をさらに悪化させます。
c) チームのエネルギーとコアビジネスへの集中:
彼らのコアバックエンドチームはわずか 8 人です。この 8 人がゲームバックエンド全体の開発、イテレーション、リリース、障害対応を担当しなければなりません。このような状況で、貴重なエネルギーを「超大規模で高可用性な監視プラットフォームの維持」に投入するより、SLA が保証され、すぐに使えるマネージドサービスを購入する方が明らかに得策です。ここでの「面倒」とは、「初期インストールの複雑さ」ではなく、「大規模化後の長期的な運用コストとリスク」を指しているのです。
優先リージョンのインスタンスが「売り切れ」を検知すると、システムは自動的に容量がより豊富な
us-east-1(米国東部 1)リージョンに切り替えてサーバーを作成します。 ここは問題ないのでしょうか?そのネットワーク遅延ではプレイヤーから苦情が殺到するのでは?
ご指摘の点はまさに致命的です——日本のプレイヤーのリアルタイム対戦データを処理する「リアルタイムサーバー」を東京(ap-northeast-1)から直接米国東部(us-east-1)に移した場合、150ms を超える物理的な遅延は壊滅的であり、プレイヤーは間違いなく「苦情を殺到させる」でしょう。
したがって、このメカニズムの設計と理解の鍵は、**「誰のために、いつ移行するのか」**にあります。
a) これは「ローカルプレイヤー」のためではない:
このフェイルオーバーメカニズムは、おそらく日本のプレイヤーをアメリカに移行させるためのものではありません。思い出してください、彼らの「リアルタイムサーバー」はグローバルに展開されており、世界中のプレイヤーにサービスを提供することを目的としています。
より合理的なシナリオは次のようになります:
ヨーロッパのフランクフルトリージョン(eu-central-1)の C7g インスタンスも、ヨーロッパのプレイヤーが大量に流入したために売り切れたとします。この時、ヨーロッパにいるプレイヤーにとって、マッチングシステムはいくつかの選択肢に直面します:
- 失敗: プレイヤーにルーム作成失敗を伝える。(最悪の体験)
- 遠距離マッチング: 同じく満杯の東京リージョンにマッチングさせる。(遅延 > 200ms)
- 次善のマッチング: **米国東部(us-east-1)**でルームを作成させる。
ヨーロッパから米国東部への遅延も高い(約 80-100ms)ですが、東京への遅延よりははるかにましであり、トップレベルの競技ゲームでなければ、この遅延は許容可能な「次善」の範囲内です。少し遅延があってもプレイできるゲームは、サーバーがなくて全くプレイできないゲームよりはるかにましです。
b) これは「グレースフルデグラデーション」であり、「通常操作」ではない:
このメカニズムは、「リソース枯渇」という極端で稀なピーク時にのみトリガーされる最後の砦です。その核心的な目標は**「サービスの可用性(Availability)」**を保証すること、つまり、いかなる状況でもプレイヤーがルームを作成してプレイできるようにすることです。ゲームのリリース初期のトラフィックの洪水の中では、たとえ一部のプレイヤーの体験を犠牲にしても、可用性を保証することが何よりも優先されます。
c) インテリジェントなマッチングシステムの連携:
彼らのマッチングシステム(Matchmaker)は十分にインテリジェントであると推測できます。常にプレイヤーにとって物理的に最も近く、遅延が最も少ない利用可能なサーバーを優先的に探します。最適なリージョンと次善のリージョンの両方にリソースがない場合にのみ、この「大陸を越えたサーバー作成」という最終手段が発動されます。東京にいるプレイヤーに対しては、システムは常に ap-northeast-1 での作成を優先し、次に韓国のソウル ap-northeast-2 を試す可能性はありますが、アジアに選択肢があるにもかかわらず、直接米国東部に飛ぶことは決してありません。