
背景
语音聊天是需要“长生命周期连接”(long connection lifecycle)的应用,这类服务迁移到 Amazon EKS 上是非常困难的。索尼互动娱乐(SIE)关于 PSN 语音聊天服务器迁移的分享的深度在一众大量注水的演讲之中(某整车厂到现在还在上云,进度 50%)给我留下很深的印象,让我想起了和 Kubernetes 战斗的岁月,废话不多说,进入议题吧。
议题(Agenda)
- 说明长连接应用在容器化和云原生化过程中普遍面临的挑战,特别是“会话连续性”和“弹性伸缩”。
- 如何利用 Agones 解决这些挑战,并成功将语音聊天服务器迁移到 Amazon EKS。
- 如何在对用户影响最小的情况下,平滑、灵活地进行流量迁移。
长连接应用的挑战
长连接应用的特性
- 客户端与同一个服务器建立并维持一个长期会话,并且在会话中保持状态。
- 服务器必须为每个会话维持运行状态,因此会话期间的任何服务器中断都会严重损害用户体验 (UX)。
- 无论是扩容(Scale-out)还是缩容(Scale-in),都必须优先考虑会话的连续性。
长生命周期连接应用场景举例
- 使用 WebSocket 的常时连接应用(比如在线协作工具、消息推送)。
- 其他实时通信系统,如游戏服务器、视频聊天。
- 使用 gRPC streaming 进行双向通信的微服务。
- 需要与大量 IoT 传感器或设备保持连接的服务器。
PSN 语音聊天服务器的特性
- 除了前面提到的会话连续性,它还强调了流量的“尖峰(Spike)”特性,图表中的曲线形象地展示了流量在高峰和低谷间的剧烈波动。
- 为了实现实时性,通信协议采用了UDP。这带来了两个关键点:
- 客户端是直接和服务器通信,不经过负载均衡器(Load Balancer);
- 因此,必须有一种机制,能把服务器的公网 IP 地址和端口号通知给客户端。
架构痛点
在 Amazon EC2 上运维的痛点
- 成本优化困难:在维持会话的同时进行缩容(Scale-in)非常困难,导致无法有效利用 AWS 的自动缩容功能来省钱。而且,EC2 实例(虚拟机)的启动速度比容器慢,为了应对突发流量(Scale-out),必须预留更多的冗余服务器,进一步增加了成本。
- 认知负担:PSN 团队的其他服务已经上了 EKS,拥有云原生的 CI/CD 流程。而语音聊天这块“技术孤岛”还停留在 EC2,团队需要维护两套完全不同的技术栈和运维体系,这带来了巨大的“认知负担”(Cognitive Load)和维护成本。
原生 Kubernetes 的三大核心障碍
- 会话连续性的保障:Pod 的重新调度或因故障重启,都会中断正在进行的会话,影响用户。
- 缩容/扩容的控制:自动缩容(Scale-in)可能会“误杀”正在服务用户的 Pod。而扩容(Scale-out)如果不够快,又会导致新用户排队或连接失败。
- UDP 通信的处理:在 K8s 中,要把一个 Pod 的 UDP 端口暴露给公网本身就很麻烦。而且 Pod 的 IP 和端口会因为扩缩容、重新调度而改变,如何将这个动态地址通知给客户端是个大难题。
解决方案:Agones

- 一个为游戏服务器设计的、开源的 Kubernetes 扩展。
- 工作原理:通过自定义资源(CRD, Custom Resource Definition)和自定义控制器(Custom Controller)来扩展 K8s,让 K8s 能理解和管理“会话型、实时通信”应用(即 GameServer Pod)的生命周期。
核心能力
- 保护会话中的 Pod:Agones 为 Pod 赋予了会话状态,能确保一个正在服务用户的 Pod 不会被随意终止,从而保障了会话连续性。
- 提前确保 Pod 资源:通过
Fleet和FleetAutoscaler功能,可以维持一个“热身完毕”的 Pod 缓冲池。当流量高峰来临时,能立刻分配新服务器,解决了扩容延迟的问题。 - 为 Pod 分配公网 IP 和 UDP 端口:Agones 可以直接为每个 Pod 分配独立的公网 IP 和 UDP 端口,让客户端可以直连,完美实现了之前提到的 UDP 直连模型。
- K8s 的“会话保障”难题 -> Agones 用状态保护来解决。
- K8s 的“扩容延迟”难题 -> Agones 用缓冲池(Fleet)来解决。
- K8s 的“UDP 直连”难题 -> Agones 直接为 Pod 分配 IP 和端口来解决。
架构图
迁移前的 EC2 架构 - “Before”
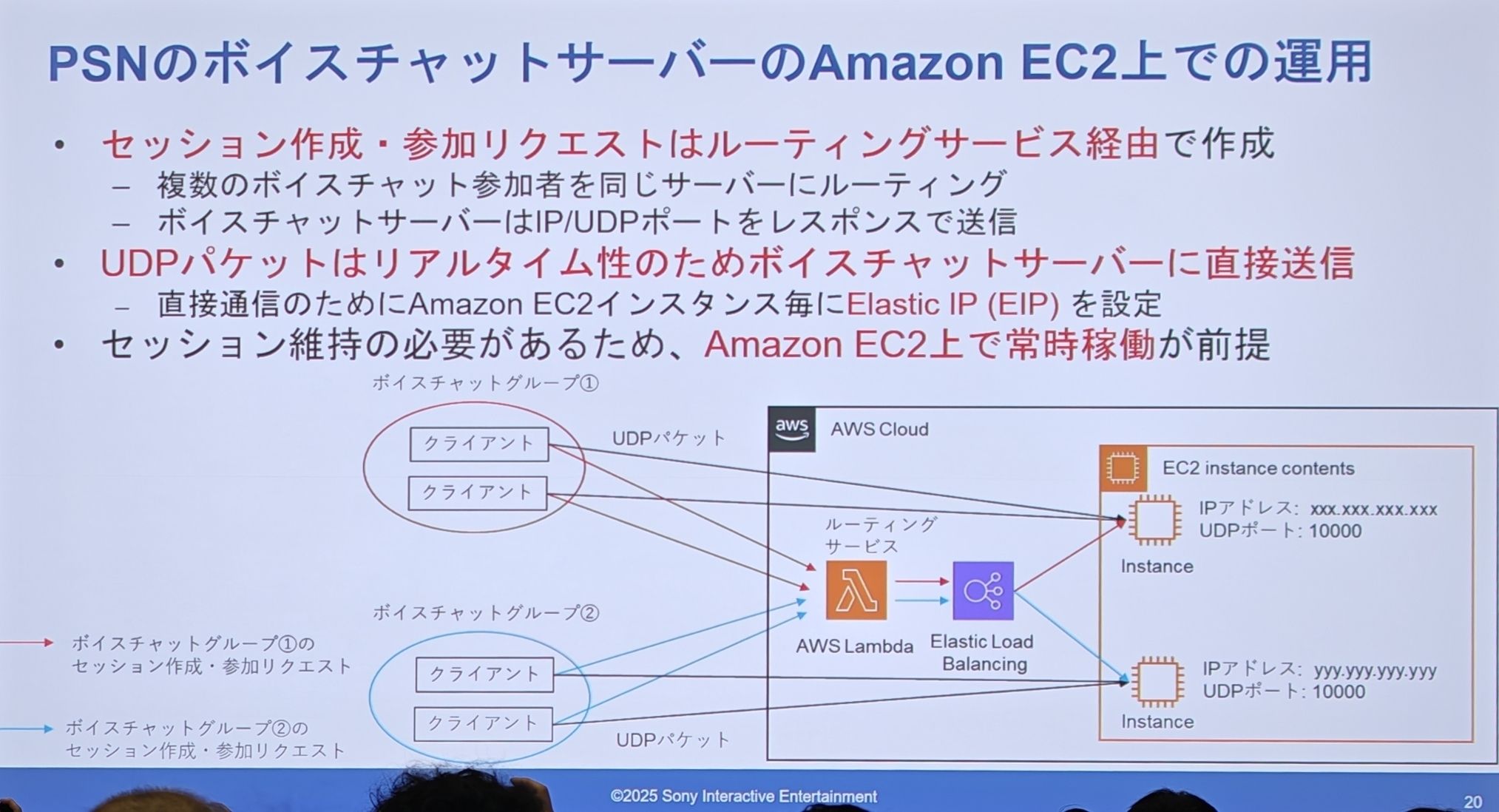
- 客户端的“创建/加入会话”请求,会通过一个“路由服务”(图上显示是 AWS Lambda + ELB)来处理。
- 路由服务负责把同一个聊天组的多个用户,都指向同一个 EC2 服务器。
- 为了实现 UDP 直连,每台 EC2 实例都配置了固定的弹性公网 IP(EIP)。
- 客户端拿到 IP 和端口后,就绕过路由服务,直接向 EC2 服务器发送 UDP 数据包。
迁移后的新架构图 - “Now”
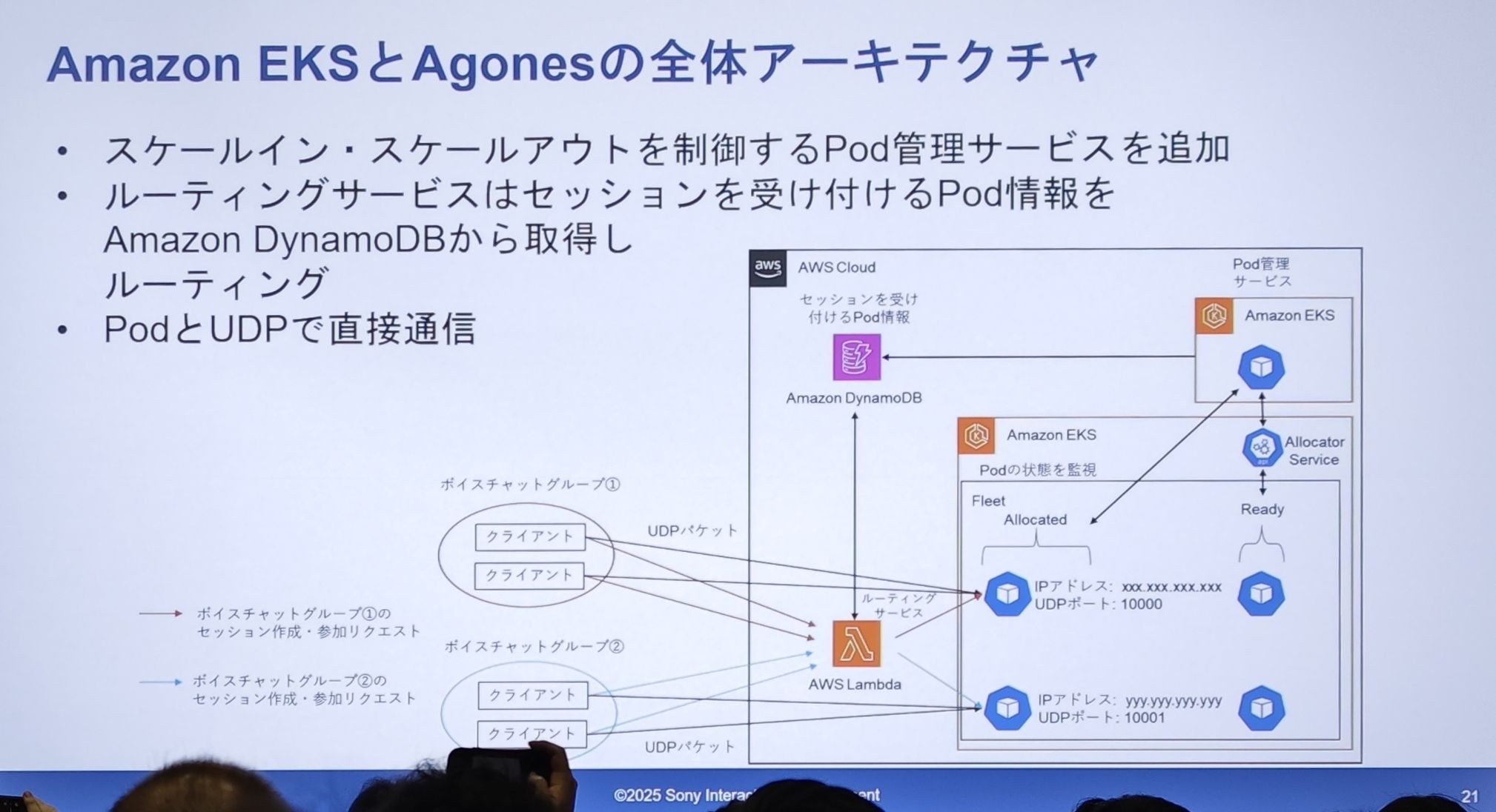
- Pod 管理:在 EKS 中,Agones 的
Fleet(舰队)会维护一个Ready(就绪)状态的 Pod 缓冲池。 - 会话分配:当路由服务(Lambda)收到会话请求时,它不再直接访问服务器。它会请求 Agones 的
Allocator Service(分配器服务),分配器从Fleet中取出一个Ready的 Pod,将其状态变为Allocated(已分配)。 - 信息中转:这个被分配的 Pod 的连接信息(公网 IP、UDP 端口)被存入了一个Amazon DynamoDB表中。
- 路由逻辑:路由服务(Lambda)查询 DynamoDB,获取可用 Pod 的信息,然后返回给客户端。
- 直接通信:客户端拿到动态分配的 IP 和端口后,像以前一样,直接与这个 Pod 进行 UDP 通信。
- 核心解耦:通过引入 DynamoDB 作为“服务注册中心”,它完美地解耦了服务请求(控制面)和服务实例(数据面)。
- 动态替换:EC2 实例被换成了 EKS 中的 Pod,固定 EIP 被换成了动态分配的 IP。
- 智能调度:Agones 扮演了“智能调度官”的角色,负责 Pod 的生命周期管理和缓冲,确保了高性能和高可用性。
深入会话分配
Agones 的设计(专用 Pod)
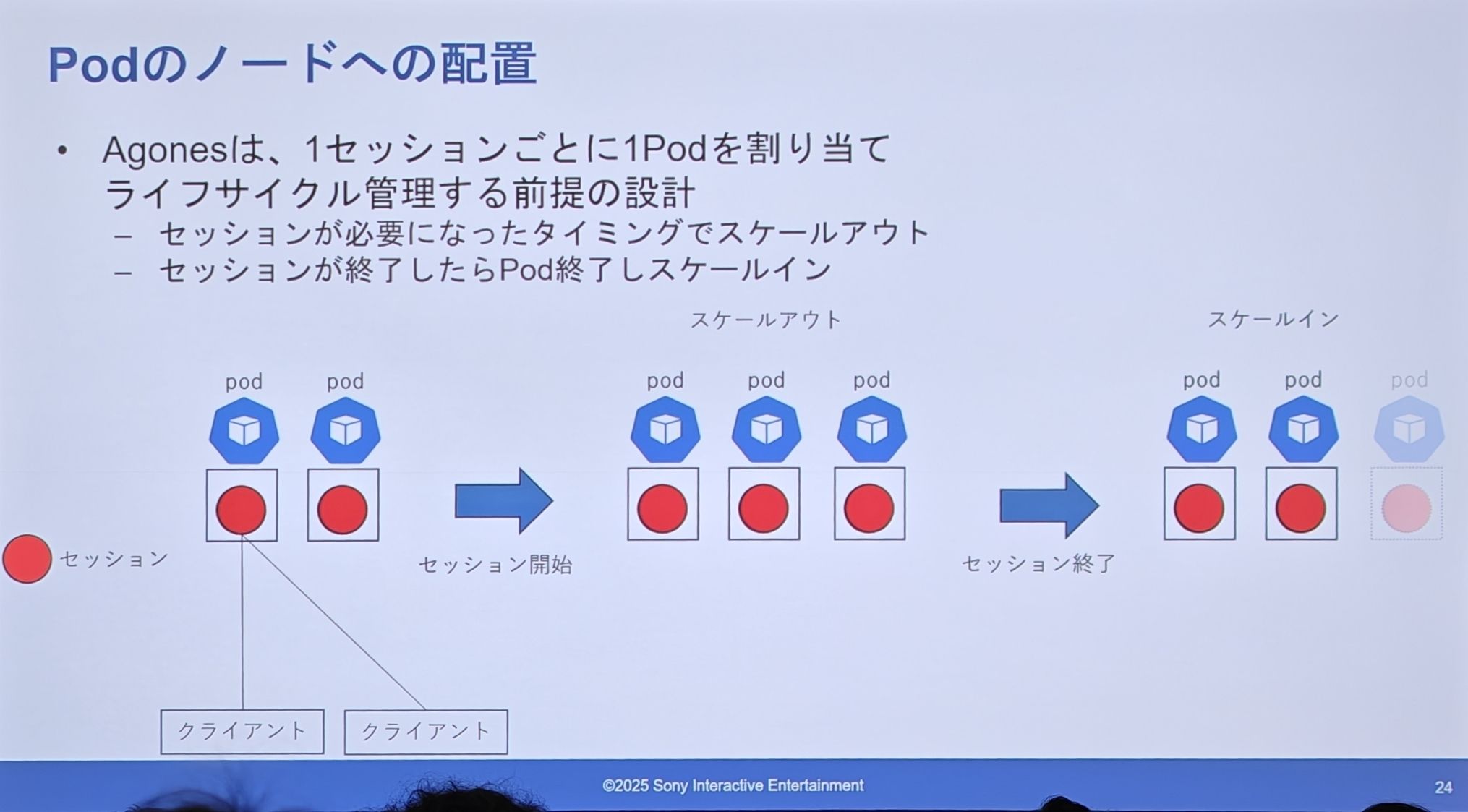
- 一个会话 = 一个 Pod:Agones 的设计前提是,为每一个独立的会话分配一个专属的 Pod。
- 按需伸缩:当需要新会话时,就从缓冲池里拿一个 Pod 出来(扩容);当会话结束时,这个 Pod 就被销毁(缩容)。
专用 Pod 的问题是什么:
- 服务器成本增加:这个模型其实很“奢侈”。一个会话可能用不完一整个 Pod 的最小资源(特别是 CPU),造成浪费。而且,每个 Pod(即每个会话)都必须带一个 sidecar 容器,这本身就是巨大的开销。
- 对基础设施的影响:
- VPC 内 IP 地址枯竭:如果有数百万个在线会话,就意味着需要数百万个 Pod IP,这会给 VPC 的 IP 地址池带来巨大压力。
- 对 etcd 和插件的负载:Kubernetes 集群的元数据都存在 etcd 里。数百万个 Pod 的创建和销毁,会对集群的大脑(etcd)以及其他各类插件造成沉重的性能负担。
PSN 的实际设计(共享 Pod)
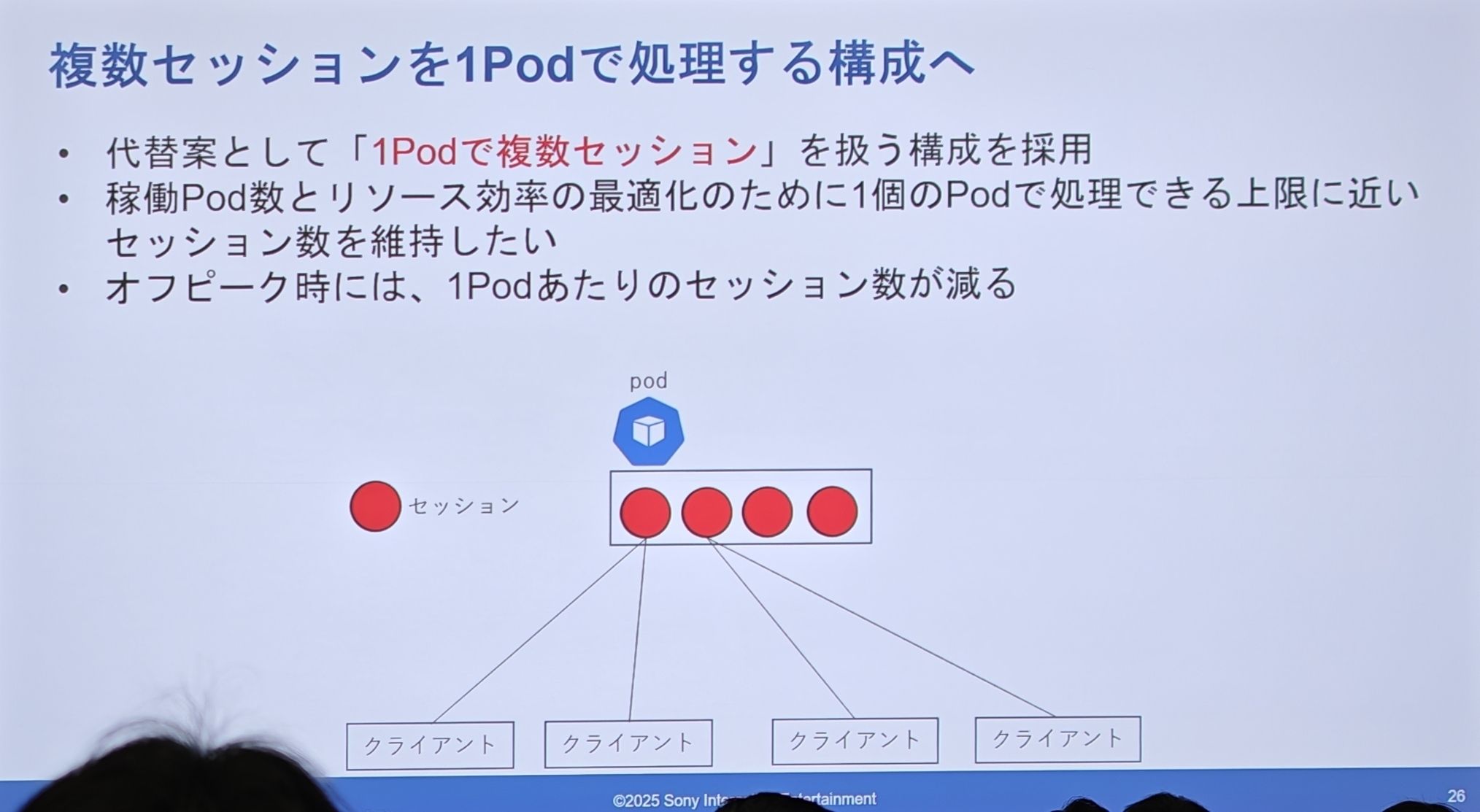
- 目标是为了优化资源效率,让每个 Pod 尽可能地满负荷运行。
- 在非高峰期,每个 Pod 承载的会话数会自然减少。
- 1 个 Pod 内部,运行着多个独立的会话。这本质上是在 Pod 内部实现了一个轻量级的调度和管理层。
然而共享 Pod 下的扩缩容变得非常复杂:
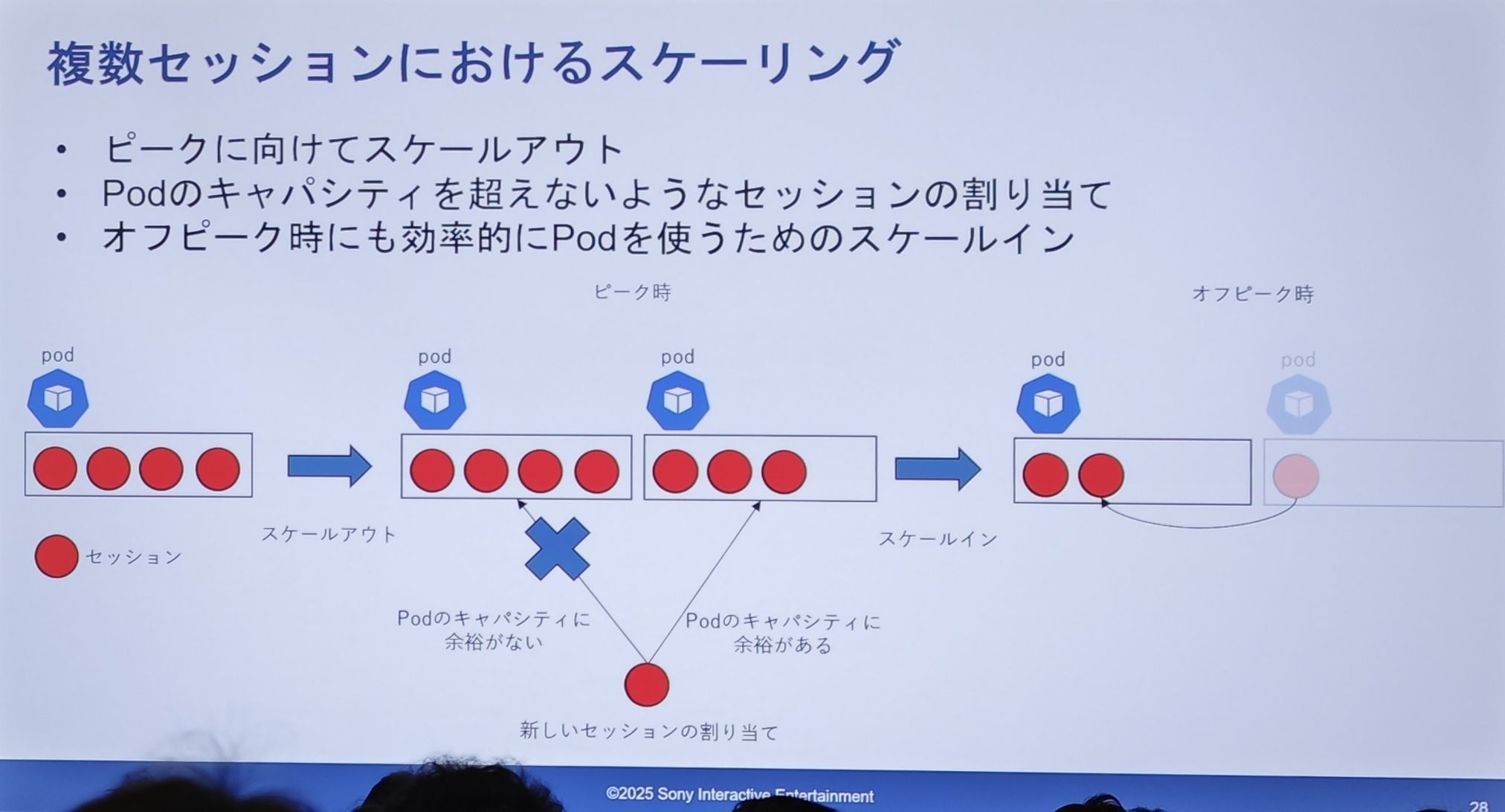
- 扩容(Scale-out):为应对高峰而扩容 Pod 数量。当新会话请求来时,会寻找一个还有“容量”的 Pod 进行分配。图上显示,一个满载的 Pod 会拒绝新请求,而有空位的 Pod 会接受。
- 缩容(Scale-in):为了在非高峰期有效利用 Pod,需要进行缩容。图上展示了“会话合并”的过程:一个 Pod 上的会话可以被迁移到另一个有空位的 Pod 上,然后将完全空闲的 Pod 进行销毁。
Agones 的设计(Pod 状态机)
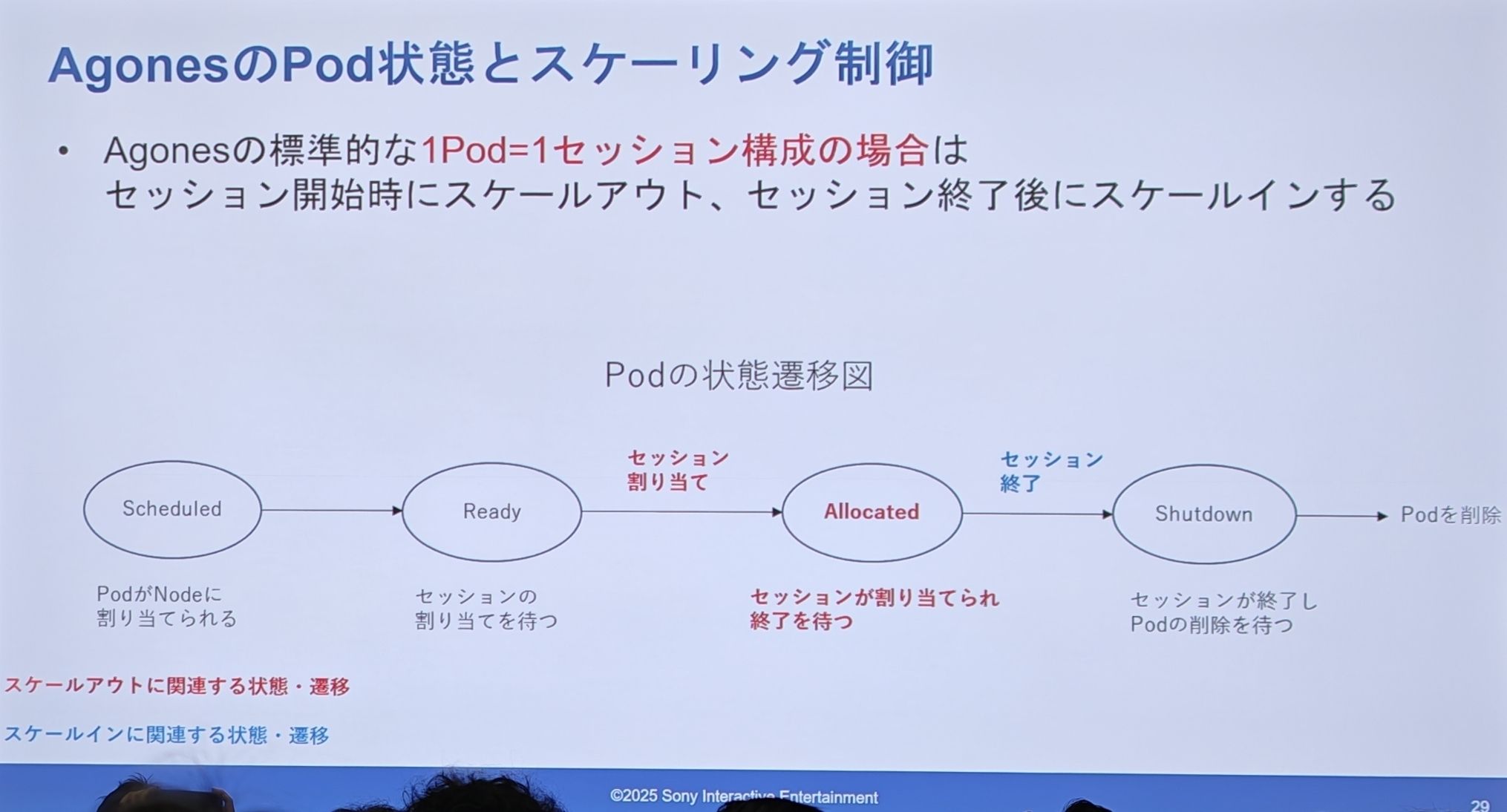
-
Scheduled (已调度) -> Ready (就绪,等待分配) -> Allocated (已分配,正在服务会话) -> Shutdown (关闭中) -> Pod 删除。
-
扩容(Scale-out)发生在会话开始时(Ready -> Allocated),缩容(Scale-in)则发生在会话结束后。
PSN 的实际设计(Pod 状态机)
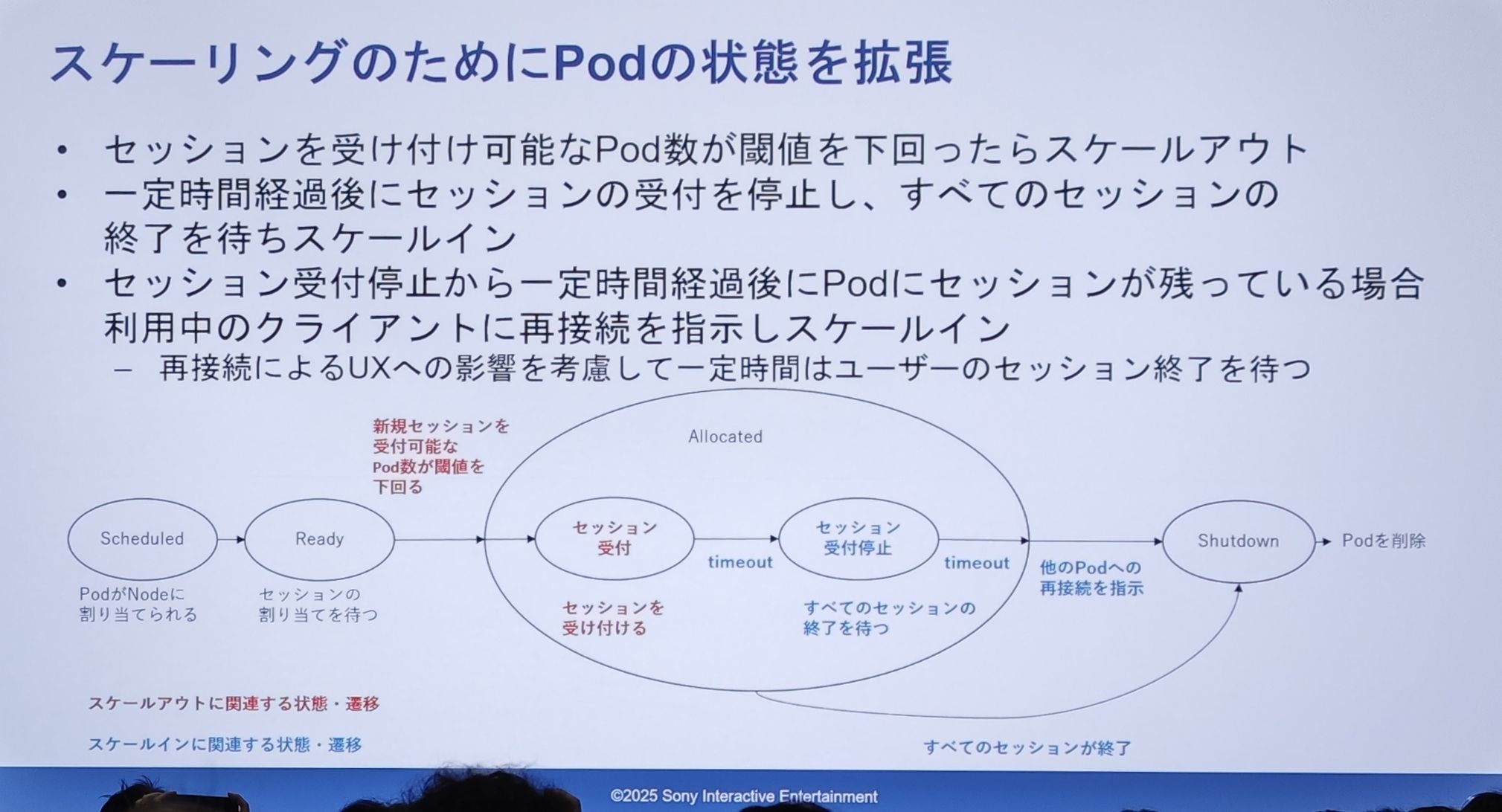
- 扩容逻辑:当可用于接收新会话的 Pod 数量低于某个阈值时,就触发扩容。
- 缩容逻辑(精髓所在):
- Pod 首先进入“停止接收新会话”状态。
- 然后等待一段时间,让 Pod 内的现有会话自然结束。
- 如果在超时后,Pod 内仍有会话存在,系统会主动向这些“逗留”的客户端发送“请重新连接”的指令,引导他们迁移到其他 Pod。
- 直到所有会话都结束后,Pod 才会进入
Shutdown状态,最终被删除。
缩容实现细节:Fleet Autoscaler
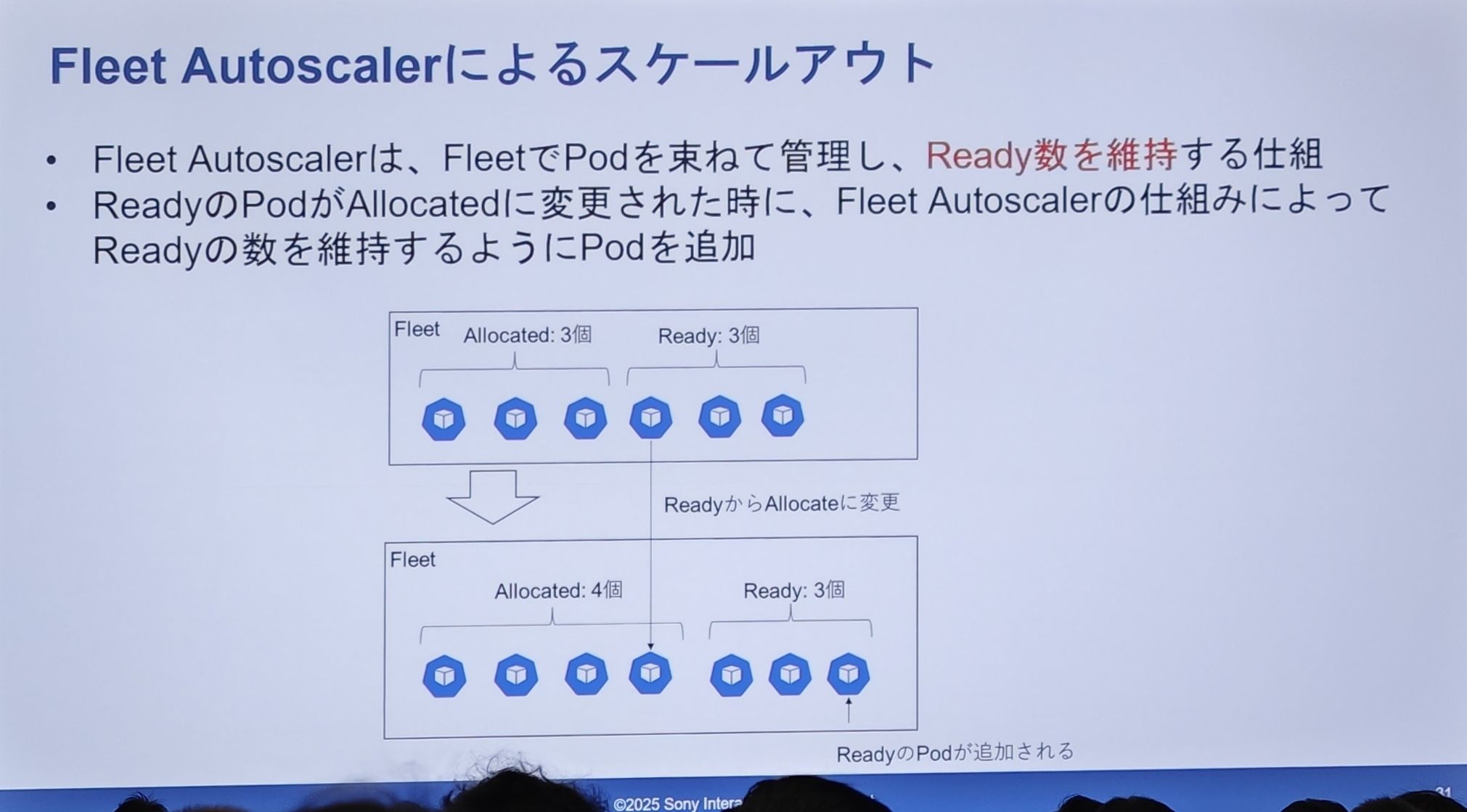
Fleet Autoscaler会监控一个Fleet(Pod 舰队)中Ready状态的 Pod 数量。- 当一个
Ready的 Pod 因为被分配给会话而转为Allocated状态时,Ready的 Pod 数量就会减少。 Fleet Autoscaler会立刻检测到这一点,并自动创建一个新的 Pod,以补充Ready缓冲池,使其数量维持在预设的水平。
- 当一个
Ready 池从 3 个减到 2 个时,系统立刻补充 1 个,使其恢复到 3 个。这确保了无论何时,总有“虚位以待”的服务器,从而保证了极低的用户等待时间。
Agones 的设计(会话分配)

- 标准的 Agones 流程是:收到会话请求 -> 调用 Allocator 服务将
Ready的 Pod 变为Allocated-> 分配请求。 - 这个 Allocator 服务是批量处理请求的,这会带来最高 500 毫秒的延迟。
- 对于语音聊天这种实时应用,启动时有半秒的延迟是不可接受的,会严重影响用户体验。
PSN 的实际设计(会话分配)

核心解决思路:解耦! 将“用户请求会话”这个需要极速响应的操作,与“系统分配 Pod”这个相对较慢的后台操作分离开。
- 用户的会话请求(通过 Lambda)不再直接触发 Pod 分配。
- Lambda 去查询 DynamoDB,从一个已经预先分配好、可随时接收会话的 Pod 列表中,立刻获取一个可用的 Pod 信息。
- 而那个耗时 500ms 的分配操作,由“Pod 管理服务”在后台提前、主动地完成,并把分配好的 Pod 信息注册到 DynamoDB 的列表中。
Ready Pod 缓冲池之上,又构建了第二个缓冲池——一个由 Allocated 状态的、随时可以接客的 Pod 组成的缓冲池(即 DynamoDB 里的列表)。用户的请求永远是从这个热备份的“二级缓冲”里拿数据,从而完美地将后台 500ms 的延迟对用户隐藏了起来。
扩容实现细节:何时触发自动扩容

- 何时停止接收会话:单个 Pod 如果 CPU 使用率或承载的会话数满了,就停止接收新会话,并从 DynamoDB 的可用列表中移除。
- 何时触发后台扩容:Pod 管理服务会持续监控 DynamoDB 中“可接待新会话的 Pod”数量。一旦这个数量低于某个设定的阈值,它就会立刻向 Agones 的 Allocator 服务发出请求,申请新的 Pod,走完那套 500ms 的流程,然后将新鲜出炉的 Pod 补充到 DynamoDB 的列表中,以备后用。
这就是他们自定义的“二级自动扩缩容”逻辑。我可以用一个比喻来解释:
- Agones:像是面粉厂,负责源源不断地生产“面团”(
ReadyPod)。 - Pod 管理服务:像是面包店的后厨,它会预估客流量,提前把“面团”烤成“面包”(
AllocatedPod),并摆在柜台上。 - 路由服务 (Lambda):像是前台服务员,顾客(用户)一来,直接从柜台上拿一个现成的“面包”给他,完全不用等后厨现烤。
- 这个“Pod 管理服务”就是面包店的店长,他盯着柜台上的面包数量,一旦少了就马上去后厨催单。这是一个非常成熟、鲁棒性极强的两级缓冲扩容体系。
缩容实现细节: “优雅缩容”(graceful draining)
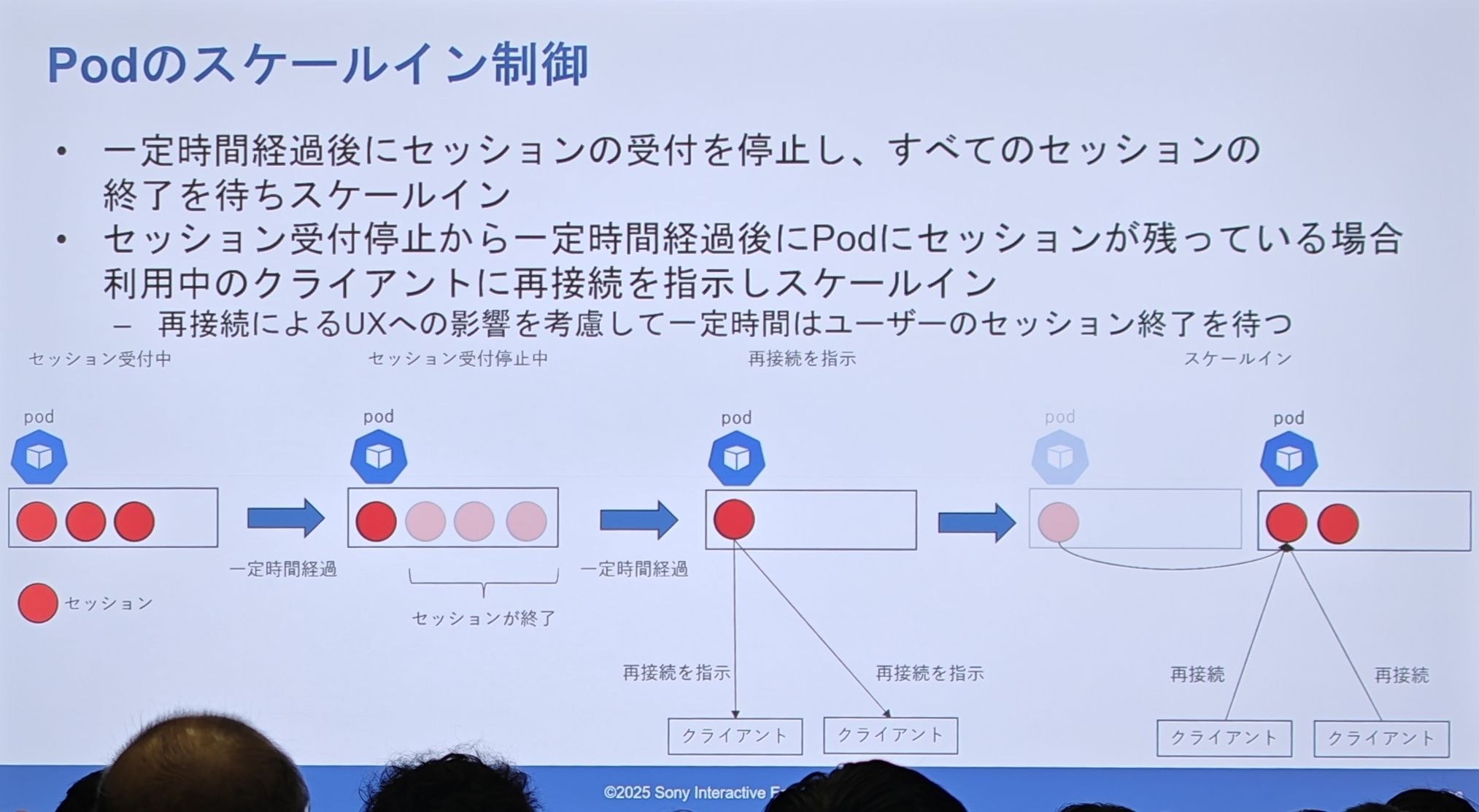
- 一个 Pod 正常服务多个会话。
- 系统决定将其缩容,于是 Pod 进入“停止接收新会话”模式。
- 在一段时间内,部分会话自然结束,Pod 上的负载降低。
- 超时后,对于仍然存在的“钉子户”会话,系统主动发出“请重连”指令。
- 客户端收到指令后,重新请求路由服务,并被分配到新的、健康的 Pod 上。
- 原 Pod 被彻底清空,最终被安全删除。
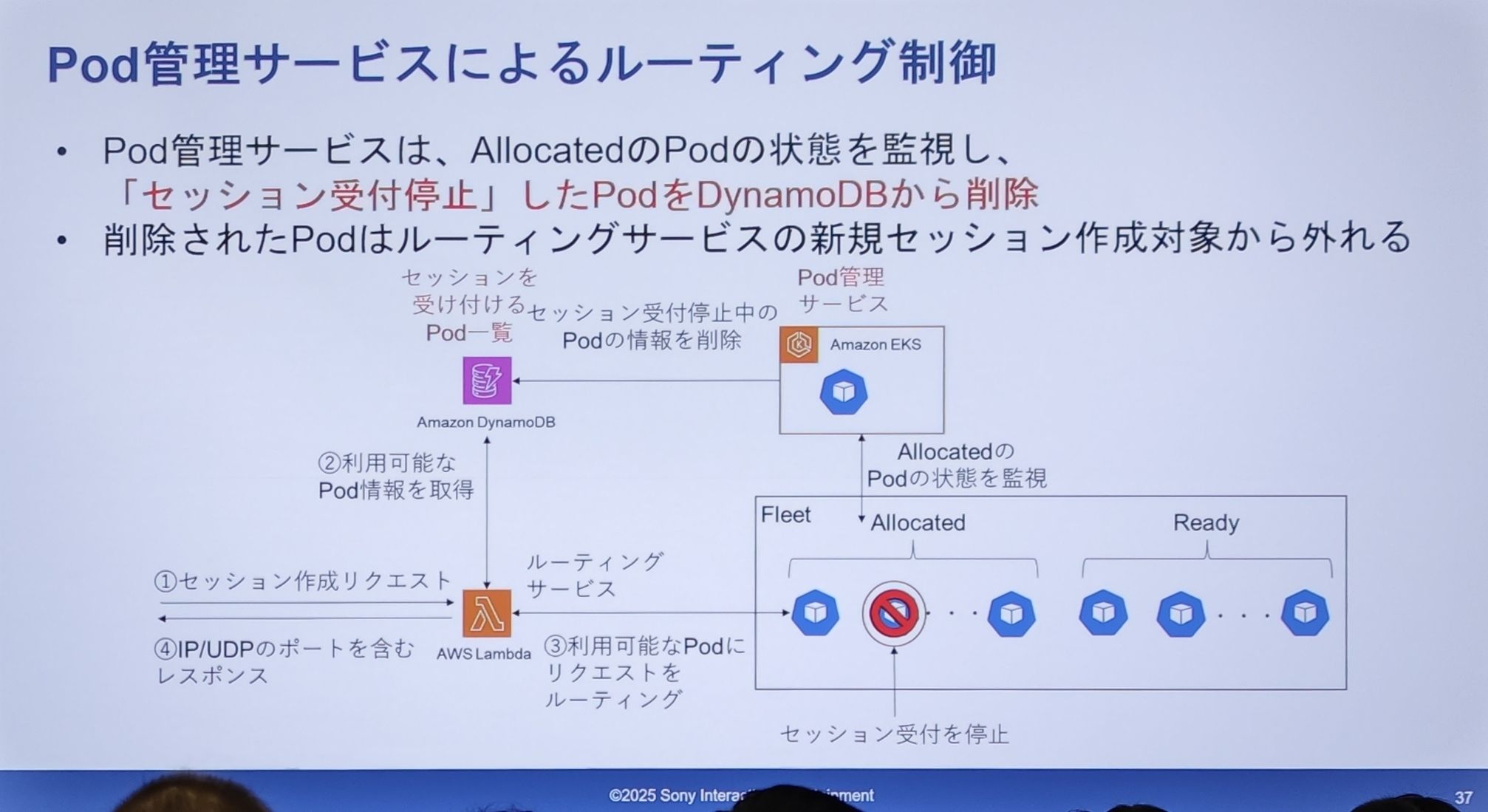
- 当 Pod 管理服务监测到一个
Allocated状态的 Pod 需要停止接收会话时(比如因为它满了,或者被选中为缩容对象),它会直接从 DynamoDB 的可用列表中,删除这个 Pod 的信息。 - 一旦信息被删除,路由服务(Lambda)在查询 DynamoDB 时就再也找不到这个 Pod 了,自然也不会把任何新的会话请求发给它。
语音聊天服务器的容器化

-
网络:因为是 UDP 通信,他们使用
hostPort方式,直接把 Pod 的端口暴露在宿主 Node 节点上。IP 地址则使用了附加在Node上的 EIP。 -
集成:Agones SDK 是以Sidecar(边车)容器的模式,和主应用容器一起打包在同一个 Pod 里。这个 Sidecar 负责与 Agones 控制面通信,进行状态管理和获取 IP/端口。
-
架构对比:
- 左(EC2):一个 EC2 实例一个进程,独占一个 EIP。
- 右(EKS):一个 Node 节点上可以跑多个 Pod。每个 Pod 都由“应用容器 +Agones Sidecar”组成。这些 Pod 共享 Node 节点的 EIP,但通过不同的
hostPort来区分。
IP 地址/端口获取方法
-
EC2 时代:从实例的元数据服务里获取 IP,端口号是固定的。
-
EKS 时代:通过 Agones SDK Server 获取。而为了让 Node 节点获得固定的公网 IP(EIP),他们设计了一套自动化脚本:
- 预先准备一个 EIP 池,并给这些 EIP 打上特定的 Tag。
- 在 EKS Node 启动时(K8s 组件运行前),通过
userdata脚本运行 AWS CLI 命令。 - 该命令会寻找一个带有特定 Tag 且尚未被占用的 EIP,然后将其绑定(attach)到当前启动的 Node 上。
服务上线时的课题
- 指导原则。
- 服务绝对不能中断。
- 对现有用户的影响必须降到最低。
- 万一出问题,必须有能立刻回滚的手段。
- 切换后也要持续观察,在确保安全的前提下逐步迁移。
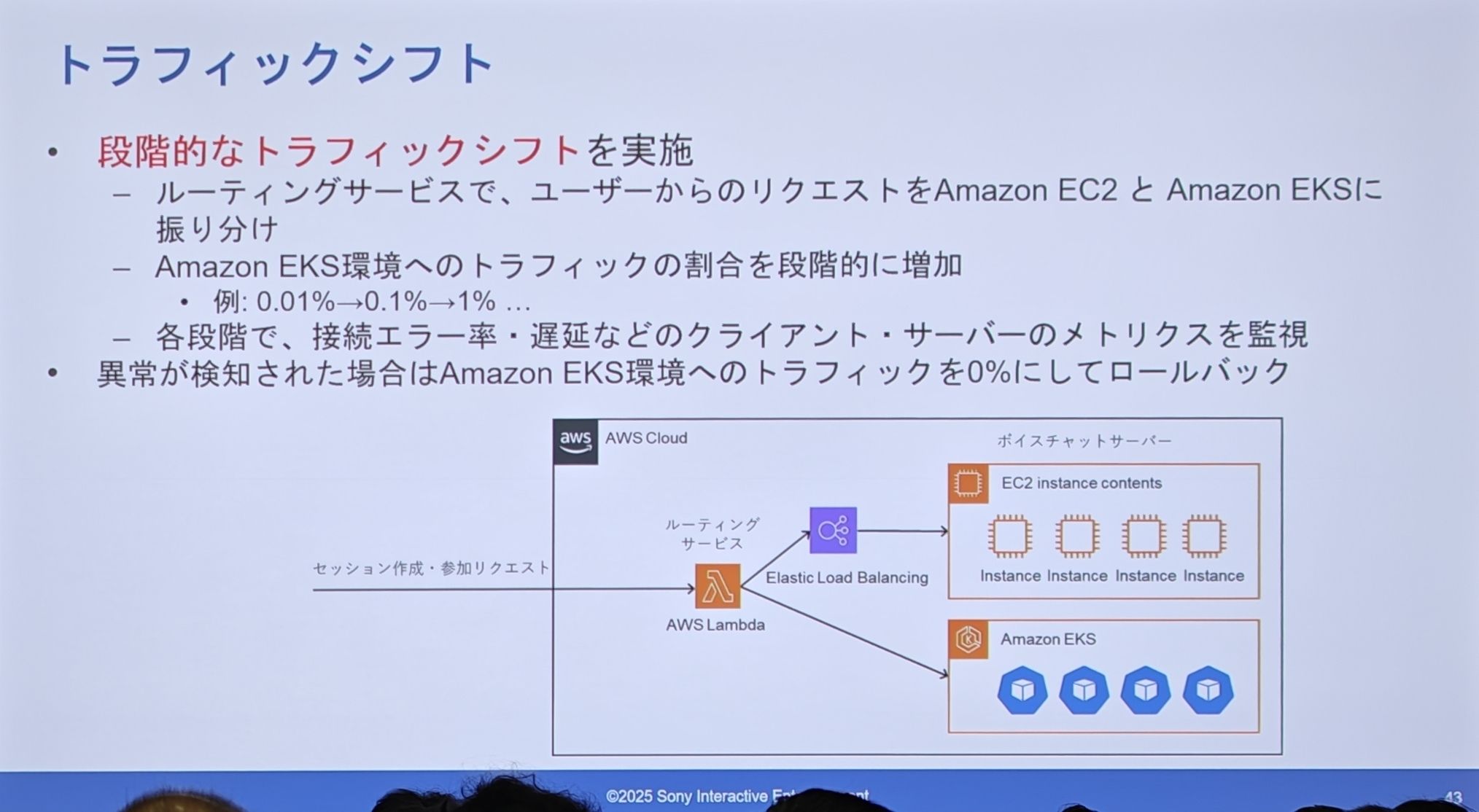
- 流量切换
- 实施阶段性的流量切换:在路由服务(Lambda)层,将用户的请求,按比例分配到旧的 EC2 集群和新的 EKS 集群。
- 逐步增加流量比例:他们极其谨慎地,从0.01% -> 0.1% -> 1% 这样一点点地把流量切到新系统上。
- 严密监控和一键回滚:在每个阶段,都密切监控连接错误率、延迟等关键指标。一旦发现任何异常,立刻将 EKS 的流量比例调回0%,实现秒级回滚。
Hybrid Cloud 化 (混合云化)
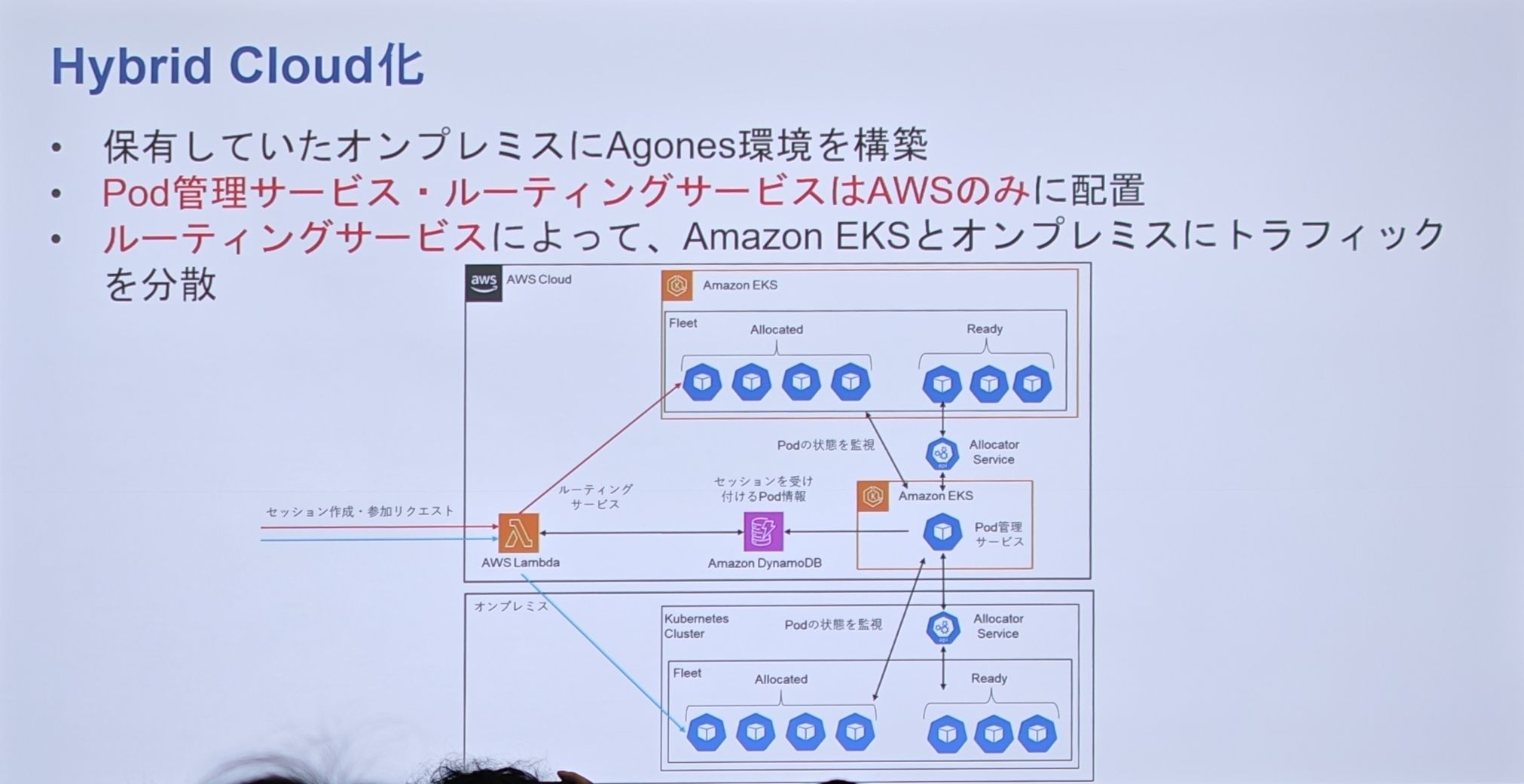
-
背景与目的:迁移到 EKS 后,成本优化成为下一个重要课题。由于语音聊天是 CPU 密集型服务,计算成本高昂。而 SIE 在全球拥有用于流媒体服务的自有本地数据中心(On-premises)。因此,他们的终极目标是利用这些本地资源,构建混合云来进一步降本。
-
混合云架构:
- 在本地数据中心里,也构建一套基于 Kubernetes 和 Agones 的环境。
- 核心的“Pod 管理服务”和“路由服务”只部署在 AWS 云端,作为统一的“控制大脑”。
- 这个云端“大脑”可以同时管理和调度流量到 AWS EKS 和本地数据中心的 K8s 集群。
总结
- 做了什么:介绍了语音聊天服务器到 EKS 的迁移和流量切换。用 Agones 解决了会话连续性、扩缩容、UDP 通信等难题,并在此基础上,通过自定义的“Pod 管理服务”实现了“1 个 Pod 多个会话”的高级模式和对延迟的极致优化。
- 怎么做的:通过阶段性的流量切换,将对用户的影响降到最低。
- 最终成果:
- 性能达标:在实现了复杂的扩缩容控制后,连接错误率和延迟与之前的 EC2 架构相比,维持了“毫不逊色”的水平。
- 效率提升:能够利用与其他服务相同的 CI/CD 流水线,降低了团队的“认知负担”,提升了开发和运维的生产力。