
背景
卡普空的「怪物猎人:荒野」在发售后仅一个月,全球累计销量便突破了 1000 万份。作为系列首次尝试支持了“跨平台游玩”的游戏,发行时达成了数百万的并发连接。玩家的真实感受如何呢?从试玩到最后正式发售,大量的声音集中在 PC 版优化不足、内容空洞和更新速度慢,但在联机的体验上却得到了正面的评价。
联机的体验非常好,不用加速器,跨平台也很稳。
怀着对「怪物猎人」,这个卡普空知名度最高的 IP 的好奇,我在「AWS Summit Japan 2025」的第二天(6 月 26 日)举办的 「モンスターハンターワイルズ 100 万以上のユーザー同時接続を支えたネットワークアーキテクチャ」 议题中,亲自听取了来自卡普空的工程师筑紫啓雄先生,分享了打造”跨平台“游戏服务器过程中,所进行的技术选型、独特的创新思路以及各种挑战。
核心挑战
怪物猎人系列前作的局限性:依赖于平台方(如 PlayStation, Steam)各自独立的网络服务,导致玩家无法跨平台一同游戏。在本作备受期待的新的目标下,自然无法通过系列以往使用的平台方网络服务来实现。为了打破这堵墙,卡普空必须亲自下场,从零构建自己的网络后端服务。这个商业决策是后续所有复杂技术选型的根本出发点。
架构
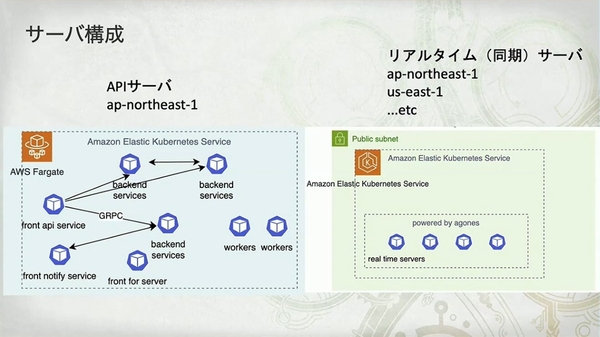
- API 服务器 (API サーバ): 部署在单一区域(图中标为
ap-northeast-1,即东京),用于处理游戏的核心逻辑和数据。 - 实时服务器 (リアルタイムサーバ): 采用全球分布式部署,专门处理玩家间的位置、动作等需要低延迟同步的信息。
- 技术栈选型:
Amazon EKSonAWS Fargate - 通信方式:前端服务(front api service)接收 HTTP 请求,而后端服务之间则通过
gRPC进行高效通信。
Amazon EKS on AWS Fargate 最大的好处是无需管理节点,极大地降低了运维负担。但代价也很明确:“サーバ (pod) の立ち上がりは遅い (1 分くらい)(Pod 启动慢,约 1 分钟)”以及“DaemonSet は使えない(无法使用 DaemonSet)”。
微服务架构确实帮助团队在高复杂度的项目中保持了敏捷性。享受微服务带来的便利,必须以克服其固有的管理和设计复杂性为代价。
- 优点 (良かったところ):
- “易于定位错误和延迟”
- “各负责人可无冲突开发”
- “可对特定服务进行独立热更新”
- 难点 (難しいポイント):
- “CI/CD 的复杂化”
- “数据操作的事务处理”
从 App Mesh 到 VPC Lattice

团队最初为了省事而选择了 AWS 托管的 App Mesh。这张图的示意图是经典的服务网格“Sidecar(边车)”模式:应用(App)的流量被同 Pod 内的 Envoy 代理拦截,再由 Envoy 代理之间进行通信。
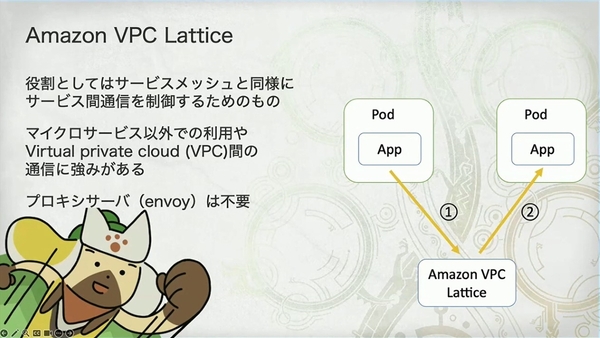
然而,就在《怪物猎人:荒野》公测(2024 年 10 月)前夕,App Mesh 宣布将停用(截止日期为 2026 年 9 月 30 日)。团队不得不紧急更换方案。这张图展示了替代品 VPC Lattice 的架构。最核心的区别在于无需 Envoy 代理,应用直接与 VPC Lattice 服务通信。
迁移后架构
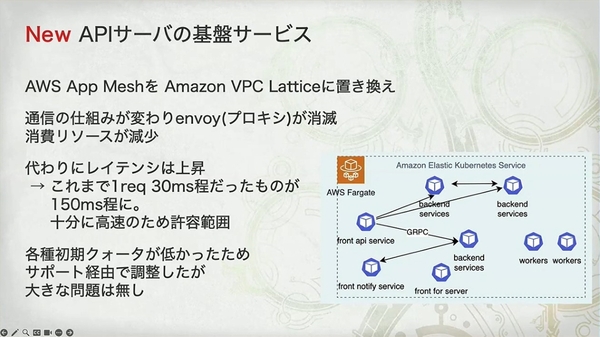
- 资源节省: VPC Lattice 无需 Envoy 边车,所以节省了这部分 Pod 的资源(“その分の pod のリソースが浮く”)。
- 延迟增加: 通信路径从“应用 -> 本地代理 -> 目标代理 -> 目标应用”变成了“应用 -> VPC Lattice 服务 -> 目标应用”。虽然图上看起来更简单,但流量绕道了一个外部的托管服务,这解释了为什么延迟会从 30ms 增加到 150ms。
团队并没有等到产品上线前才“赌一把”,而是在两次公测(OBT1 和 OBT2)之间,制定了明确的迁移和重测计划。
- 得: 移除了 Envoy 代理,降低了资源消耗。
- 失: 延迟从 30ms 上升到 150ms。
“十分に高速のため許容範囲(因为仍然足够快,所以在可接受范围内)”这一结论,说明这是一次经过深思熟虑且成功的技术权衡。
“集会所”服务器
核心任务和挑战
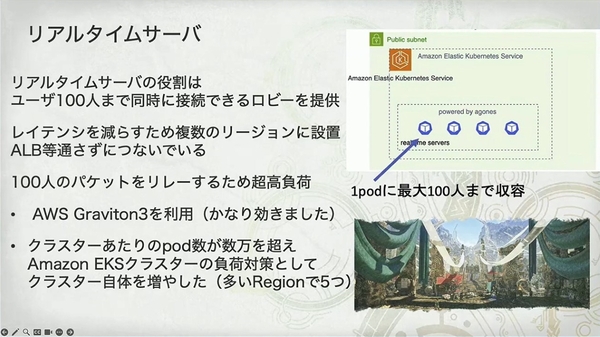
- 功能: 提供一个最多100 人同时在线的“ロビー(集会所)”。
- 特点: 需要中继 100 人的数据包,是名副其实的 “超高负载”。
- 架构策略:
- 全球部署、绕过 ALB: 为了极致的低延迟,服务器被部署在多个 Region,并且客户端直接连接,绕过了会增加延迟的负载均衡器。
- 硬件优化: 点名表扬了 AWS Graviton3 处理器,并附上“かなり効きました(效果非常好)”的高度评价,证明了 Arm 架构处理器在网络密集型应用上的性能优势。
- 集群横向扩展: 当单个 EKS 集群的 Pod 数达到数万,控制面不堪重负时,他们采用了非常高阶的玩法——增加集群本身的数量(“多い Region で 5 つ”),在单个区域内运行多个 EKS 集群来分摊压力。
独特伸缩策略
- 团队摒弃了传统的“基于 CPU/内存”的伸缩模式,而是采用了 “根据人数和条件(例如‘新手房’、‘高手房’)进行控制” 的策略。
- 这样做的原因幻灯片也给出了解释:“ユーザの動きや接続数によって消費リソースが大きく変わる(资源消耗会因用户的行为和连接数而发生巨大变化)”。例如,一个 100 人都在激烈战斗的房间,其资源消耗远高于一个 100 人都在挂机的房间。只看 CPU 无法准确反映真实需求。
- 技术实现: 他们使用 Karpenter 作为伸缩器(Scaler)。Karpenter 的“just-in-time”节点配置能力,与这种基于业务逻辑的、精细化的伸缩需求完美契合。
Episode
「Graviton3 ベースの C7g インスタンスで運用していたが、リージョンのインスタンスを使い切ってしまったことがあった。一時期、本番環境では 30 万 pod ほどを使っていた」
「怪物猎人:荒野」上线时的负载达到了一个难以想象的量级,以至于耗尽了 AWS 某个区域特定类型(C7g)服务器的全部库存。
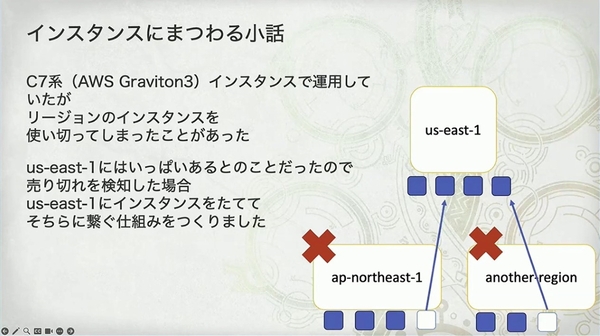
他们的解决方案:建立一个自动故障转移机制。当检测到首选区域的实例“售罄”时,系统会自动切换到容量更充足的 us-east-1(美东 1 区)去创建服务器。(没问题吗,这网络延迟玩家不得骂娘?)
数据库选型

- 数据库选型的指导思想:必须能承受“超高流量”,且在用户数未知的情况下易于扩展。
- 幻灯片清晰地列出了两大主流选择:NewSQL(兼具关系型数据库的 ACID 特性和高扩展性)与 NoSQL(模式灵活、性能优越)。
- 最关键的决策是右下角那句:“モンスターハンターワイルズでは NewSQL, NoSQL 両方を使いました(在‘荒野’中,我们两者都用了)”。
主数据库:DynamoDB
- 为何选择DynamoDB作为主数据库。原因非常典型且正确:绝大多数数据访问场景是针对单个用户的高频键值查询,例如“获取自己的好友列表”、“查询任务历史”等。这是 DynamoDB 最擅长的领域。
- 幻灯片用一种非常有趣的方式(自问自答:“需要复杂搜索吗?” -> “需要!”)引出了 DynamoDB 的短板,为引入第二种数据库埋下伏笔。
复杂搜索的难题:“救难信号”

- 玩家需要根据“游玩倾向”、“强度”、“语言”等多个维度去筛选和查找可以加入的游戏房间。
- 对数据库性能“かなりきついデータ条件(相当严峻的数据条件)”的“救难信号”搜索功能。在数百万玩家创建的、数以千万计的动态任务中进行这样多条件的组合查询,是单一的键值数据库(如 DynamoDB)难以高效完成的。
它并非简单的查询,而是:
- 条件的组合: 由“系统自动决定的条件(如怪物、地图)”和“玩家自己设定的条件(如参与人数、密码有无)”共同组成。
- 多维与低基数查询: 玩家在搜索时,可以根据怪物、任务类型、难度、语言等多个维度进行筛选。其中很多条件(如平台、语言)的唯一值很少,即“カーディナリティが低い(低基数)”,这对键值数据库的索引设计是巨大的挑战。
为何是 TiDB?

开发初期曾尝试使用 Amazon Aurora Serverless v2,但考虑到其 “最大性能” 和应用层 “水平分散的复杂さ(水平扩展的复杂性)”,最终转向了 TiDB。这说明团队需要的不仅是“能用”,而是在极限负载下依然能可靠扩展的“利器”。
- 优缺点分析:
- 优点: 无维护窗口、不停机变更规格、对应用透明的水平扩展。这些对于 7x24 小时运行的游戏至关重要。
- 缺点: 内部多层架构带来的速度略逊、存在热点时性能会受影响。
CQRS(命令查询职责分离)
数据流:
- 当玩家发起“救难信号”搜索时,请求会打到 TiDB。
- TiDB 利用其 SQL 引擎,在专门优化的“搜索表”中高效地完成多条件筛选,然后返回符合条件的任务 ID 列表。
- 应用拿到 ID 列表后,再去 Amazon DynamoDB 中进行最高效的、批量的键值查询,拉取任务的完整详细信息(如成员、状态等)。
核心优势:
- 各司其职: 让 TiDB 专心做它最擅长的复杂查询,让 DynamoDB 专心做它最擅长的高并发键值读写。
- 性能隔离: 将高负载的查询流量与常规的读写流量分离,避免相互影响。
- 成本与效率优化: 只在 TiDB 中存储必要的索引数据,大大减少了 NewSQL 数据库的存储成本和数据量,确保了查询性能。
用 DynamoDB 处理 80% 的常规、高并发键值查询,发挥其极致的性能和扩展性。
用 TiDB 解决 20% 的“硬骨头”——即“救难信号”这种复杂的多条件搜索。他们只将用于搜索的索引数据放入 TiDB,查询到目标 ID 后,再返回 DynamoDB 获取完整信息。这是一个非常经典且高效的 CQRS(命令查询职责分离)实现模式。
全链路可观测性
Prometheus+Grafana
- 技术栈: 团队选择了 Amazon Managed Service for Prometheus 和 Amazon Managed Grafana。
- 核心动机: 再次体现了务实哲学。自建 Prometheus 是“かなりのメモリ食い(非常消耗内存)”且管理麻烦,学习其查询语言 PromQL 也“かなり大変(相当费劲)”。通过采用 AWS 的托管服务,团队将宝贵的精力从基础设施运维中解放出来,聚焦于业务本身。
APM 洞察微服务

- 为何需要 APM: 采用了微服务架构,所以必须有分布式追踪(Distributed Tracing)**。
- 技术选型: 在自建 Jaeger 和 AWS X-Ray 之间,团队再次选择了“楽に構築できそうな(看起来能轻松构建)”的 AWS X-Ray。
- 价值所在:
- 图中展示的 X-Ray 服务地图,将原本错综复杂的微服务调用关系,变成了一张清晰可见的拓扑图。开发者可以直观地看到请求如何从客户端流经各个服务,以及每个环节的延迟。
- 第四张图则展示了 APM 的微观洞察力。这是一个请求的“瀑布流”追踪详情,能看到每一次
dynamodb.Get、momento.SetNXWithTTL(这里还透露了他们使用了 Momento 作为缓存服务)等下游调用的精确耗时。当出现问题时(如图中的红色感叹号),开发者可以迅速定位到具体的代码行和错误堆栈。
极限压力测试
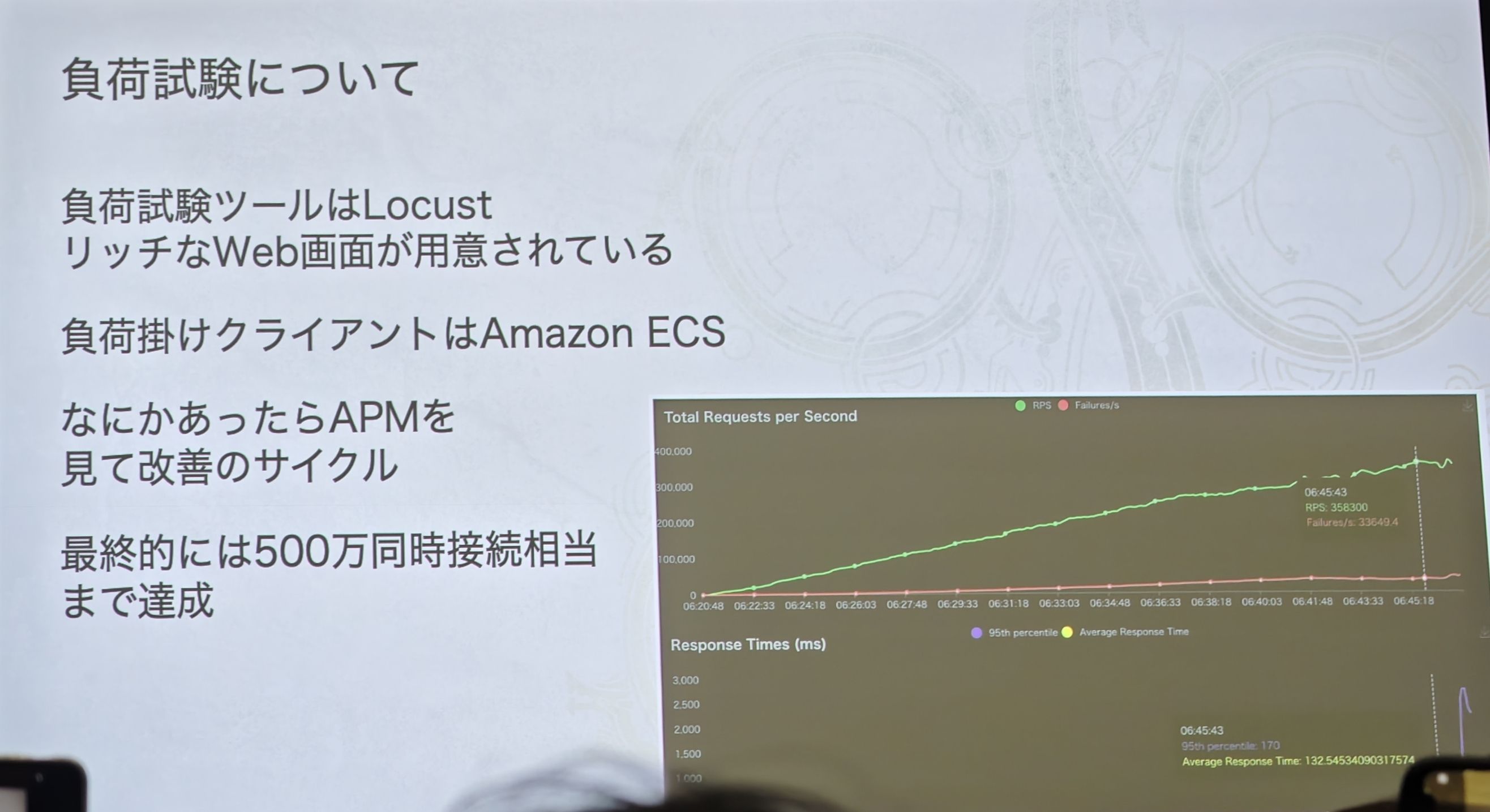
- 测试方法:
- 工具: 使用拥有丰富 Web 界面的 Locust。
- 压测客户端: 使用 Amazon ECS,正如简报所述,这可以利用 Graviton 处理器和 Spot 实例来极大降低测试成本。
- 改进循环: 幻灯片明确了他们的工作模式——**“通过负载测试发现问题 -> 查看 APM 定位瓶颈 -> 进行改进”**的闭环。
- 最终成果: 图表中的绿色线条稳步攀升,最终达到了一个惊人的数字——“500 万同時接続相当まで達成(最终达成相当于 500 万并发连接的水平)”。这个数字是所有前面讨论的架构设计——从微服务、服务网格,到实时服务器、混合数据库——最终价值的体现。
上线成功的保障:AWS Countdown Premium

- 关键作用: 这项服务在公测和正式发布等关键节点,提供了紧急响应支持。
- 实战案例: 幻灯片举了一个非常具体的例子——“監視のクォータが一部引っかかった(监控服务的某个配额用尽了)”。在流量洪峰中,这可能是致命的。
- 解决方案: 因为团队事先与 AWS Countdown 团队共享了架构和资源计划,所以在问题发生当天,AWS 就能迅速、平稳地提升配额。这充分说明了“主动沟通、提前规划”在应对超大规模事件中的重要性,它将潜在的危机消弭于无形。
- 当然,这里他们也有广告的嫌疑,只能说尊重一下主办方,哈哈。
复盘
-
最大的挑战依然是AWS 的各种资源配额(Quota),再次印证了 Countdown 服务的重要性。
-
技术上最棘手的依然是 “救难信号搜索” 功能。
-
当初为了和实时服务器的技术栈(EKS)保持一致,为 API 服务器选择了 Amazon EKS on Fargate。
-
遗憾之处: Amazon ECS 在成本上更具优势。ECS 能更灵活地利用 Spot 实例 和 Graviton 处理器 这两大“降本利器”,而这在当时的 EKS Fargate 上有所限制。
团队
- 编程语言: 团队统一使用 Go 语言。
- 团队规模: 仅仅 8 个人!这支精悍的团队,构建并运维了支撑数百万玩家同时在线的庞大后端服务。这堪称奇迹,也从侧面印证了云原生托管服务与自动化工具对提升“人效”的巨大价值。
- 工作模式: “基本的には横断で対応(基本上是横向协作)”,这表明他们是一个高度协作的跨职能团队。
提问
根据我的个人经验,自建 Prometheus 并不算太麻烦,这块我自己反而感觉是 Kubernetes 体系中相对简单的一块。我还自己改造过 kube-state-metrics,使得集群可以支持更多指标
您说的非常对,对于中小型或常规规模的 Kubernetes 集群,甚至是一些大型但业务相对单一的集群而言,基于 prometheus-operator 等工具自建 Prometheus 监控体系,确实是一个成熟且不算特别麻烦的方案。像您一样有能力去改造 kube-state-metrics 的资深工程师,自然会觉得这部分是可控的。
然而,卡普空在这里所说的“麻烦”和“消耗内存”,我认为需要结合他们史无前例的规模和极度动态的环境来理解:
a) 规模的“量级”差异:
简报中提到“某个时期,生产环境使用了约 30 万个 Pod”。30 万个 Pod,加上数万个节点(由 Karpenter 动态创建),以及背后的 EKS 控制面、网络组件、存储等,这会产生天文数字级别的时间序列(Time Series)。
当时间序列的数量(即 Cardinality,基数)达到千万甚至上亿级别时,Prometheus 的内存消耗会急剧膨胀,单台 Prometheus 实例早已无法承受。这时自建就需要引入 Thanos、Cortex 或 Mimir 等联邦集群方案来做分片和长期存储。而维护一套高可用的 Thanos 集群,处理其存储、压缩、查询网关等组件,其复杂度远超单个 Prometheus,这对于任何团队来说都是一个巨大的运维负担。
b) 业务的“动态性”:
游戏服务器是极度动态的。Karpenter 会根据玩家的“集会所”需求,在几分钟内创建或销毁成百上千的节点和 Pod。这种剧烈的变动对服务发现和指标抓取是巨大的考验,同时也产生了大量生命周期很短的时间序列,进一步加剧了高基数问题。
c) 团队精力和核心业务的聚焦:
他们的核心后端团队只有 8 个人。这 8 个人要负责整个游戏后端的开发、迭代、发布和故障处理。在这种情况下,将宝贵的精力投入到“维护一个超大规模、高可用的监控平台”上,显然不如直接购买一个有 SLA 保障、开箱即用的托管服务来得划算。这里的“麻烦”更多指向的是“规模化后的长期运维成本和风险”,而非“初始安装的复杂度”。
当检测到首选区域的实例“售罄”时,系统会自动切换到容量更充足的
us-east-1(美东 1 区)去创建服务器。这里地方没问题吗,这网络延迟玩家不得骂娘?
您指出的这点绝对是致命的——如果将处理日本玩家实时对战数据的“实时服务器”从东京(ap-northeast-1)直接转移到美东(us-east-1),那超过 150ms 的物理延迟将是灾难性的,玩家确实会“骂娘”。
所以,这个机制的设计和理解,关键在于 “为谁转移”和“何时转移”。
a) 它并非为“本地玩家”设计:
这个故障转移机制,大概率不是为日本玩家转移到美国。请回忆一下,他们的“实时服务器”是全球部署的,旨在服务全球玩家。
一个更合理的场景是:
假设欧洲法兰克福区域(eu-central-1)的 C7g 实例也因为欧洲玩家大量涌入而售罄了。此时,对于一个在欧洲的玩家,匹配系统面临几个选择:
- 失败: 告诉玩家创建房间失败。(体验最差)
- 远距离匹配: 将他匹配到同样爆满的东京区域。(延迟 > 200ms)
- 次优匹配: 将他在 **美东(us-east-1)**创建一个房间。
欧洲到美东的延迟虽然也高(大约 80-100ms),但远好于到东京的延迟,并且对于非顶级竞技的游戏来说,这个延迟尚在可接受的“次优”范围内。一个能玩但延迟略高的游戏,远比一个因没服务器而根本玩不了的游戏要好。
b) 这是“优雅降级”而非“常规操作”:
这个机制是在“资源售罄”这种极端、罕见的峰值情况下才触发的最后保障手段。它的核心目标是保证 “服务可用性(Availability)”,即在任何情况下,玩家都能创建房间玩起来。在游戏发布初期的流量洪峰中,保证可用性,哪怕牺牲一部分玩家的体验,其优先级也高于一切。
c) 智能匹配系统的配合:
可以推断,他们的匹配系统(Matchmaker)足够智能。它会永远优先为玩家寻找物理位置最近、延迟最低的可用服务器。只有当最佳区域和次优区域都无资源时,才会启用这个“跨大区创建服务器”的最终预案。对于一个身在东京的玩家,系统永远会优先在 ap-northeast-1 创建,其次可能会尝试韩国首尔 ap-northeast-2,绝无可能在还有亚洲服务器可选时,直接跳到美东。